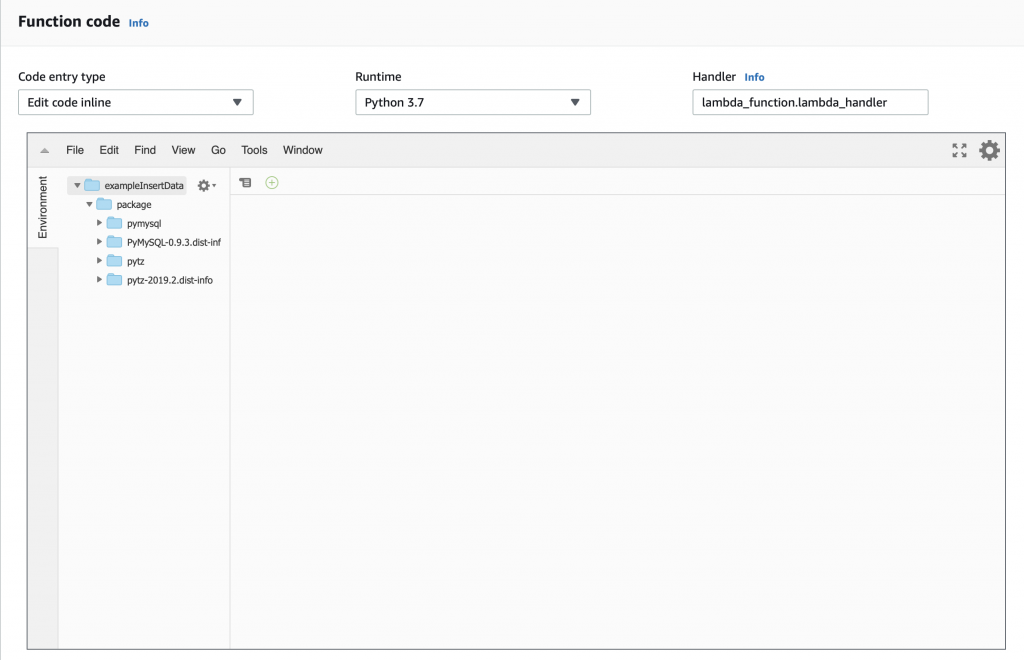
Summary
The first of several articles discussing the use of the AnyCloud BLE Stack to build advertising scanner/observers.
Story
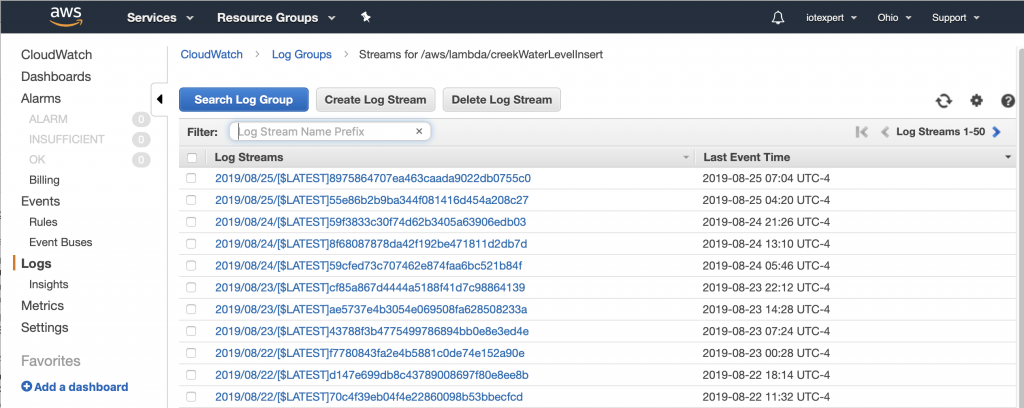
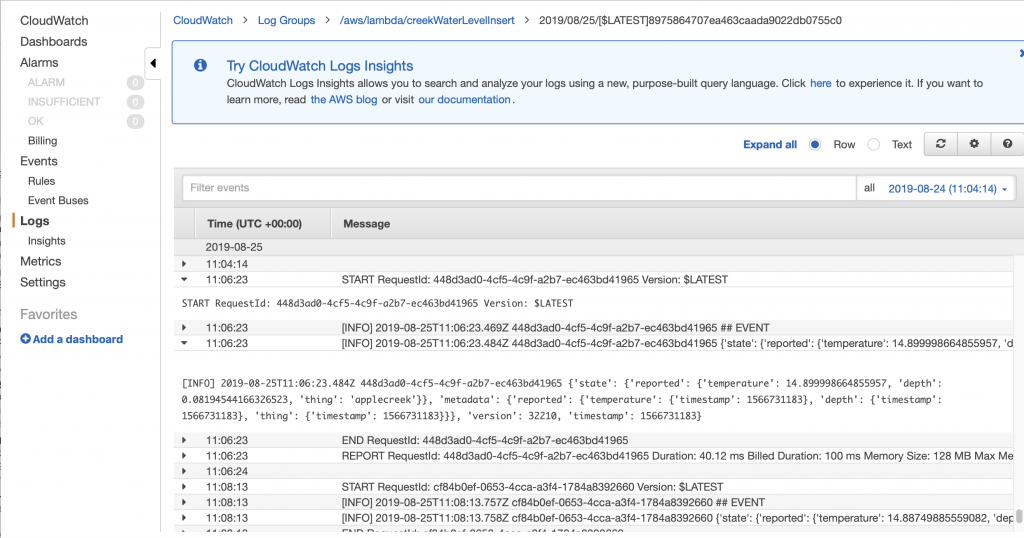
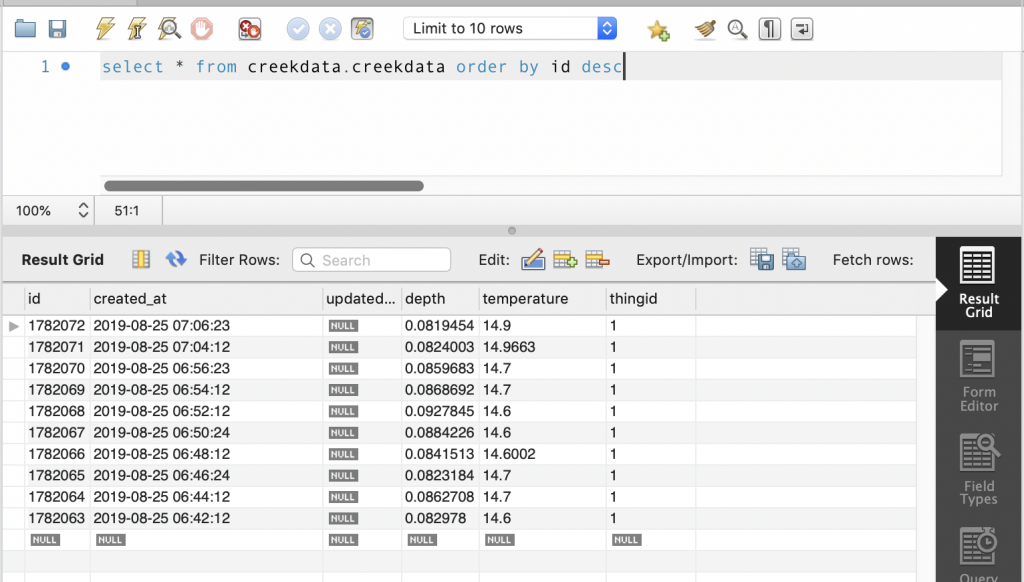
A few summers ago while I was writing the WICED Bluetooth Academy book, I created a WICED based BLE advertising scanner. Actually, I created a framework for the scanner and the remarkable summer intern I had finished the work. That project has been sitting in the source code repository for the Bluetooth class, mostly only shown to face-to-face students. This scanner is built using some of the original code combined with the new AnyCloud Bluetooth SDK. It will act sort-of-like LightBlue or one of the other Bluetooth advertising scanners you might run on your phone, but with a serial console.
Sometime in the last few months we released the Bluetooth SDK for AnyCloud (things have been crazy and I have lost track of time) This SDK has all of the stuff needed to add Bluetooth to your AnyCloud project using one of the Cypress Bluetooth/WiFi combo chips. I had not had a chance to try it out, so I decided to build a Bluetooth project and then port the scanning code.
There are
Article
Topic
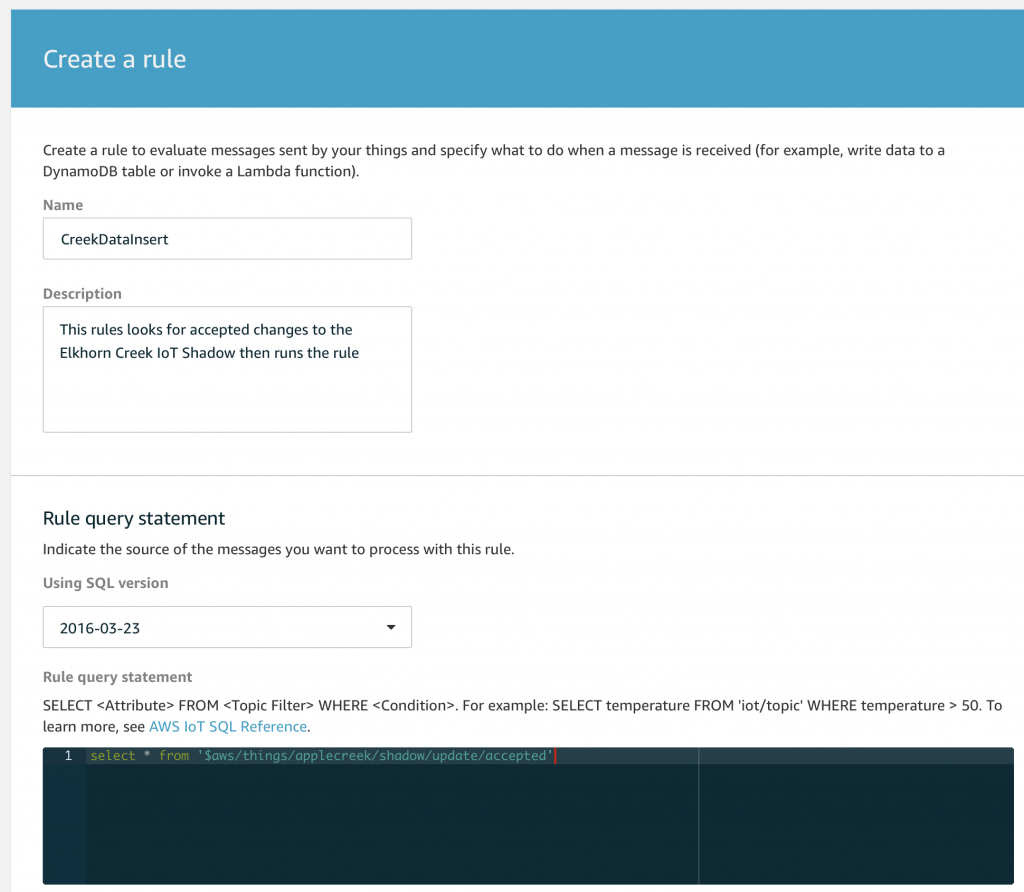
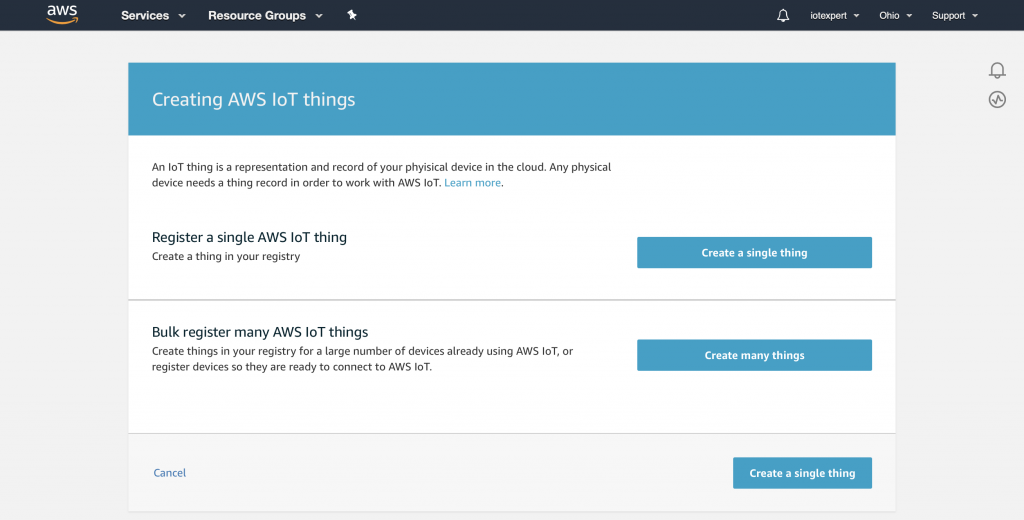
AnyCloud Bluetooth Advertising Scanner (Part 1)
Introduction to AnyCloud Bluetooth Advertising
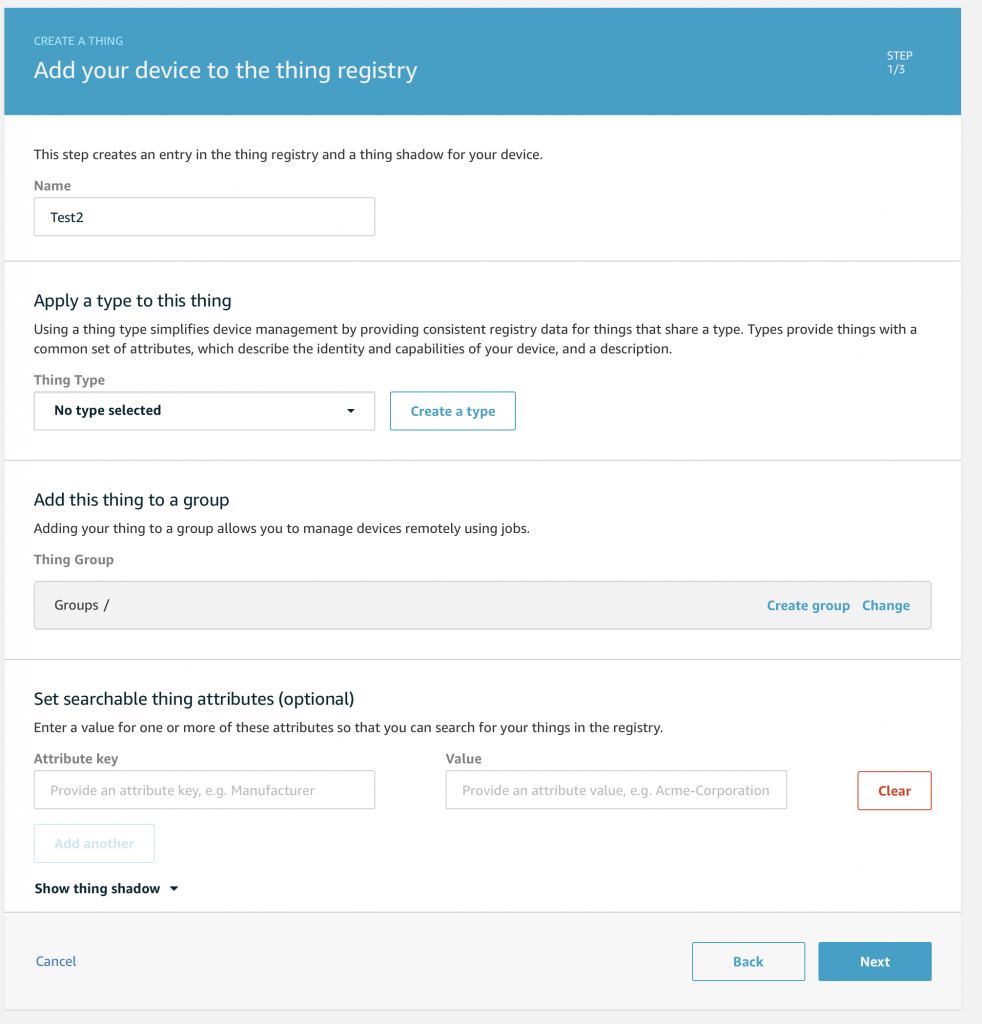
AnyCloud Bluetooth Advertising Scanner (Part 2)
Creating an AnyCloud Bluetooth project
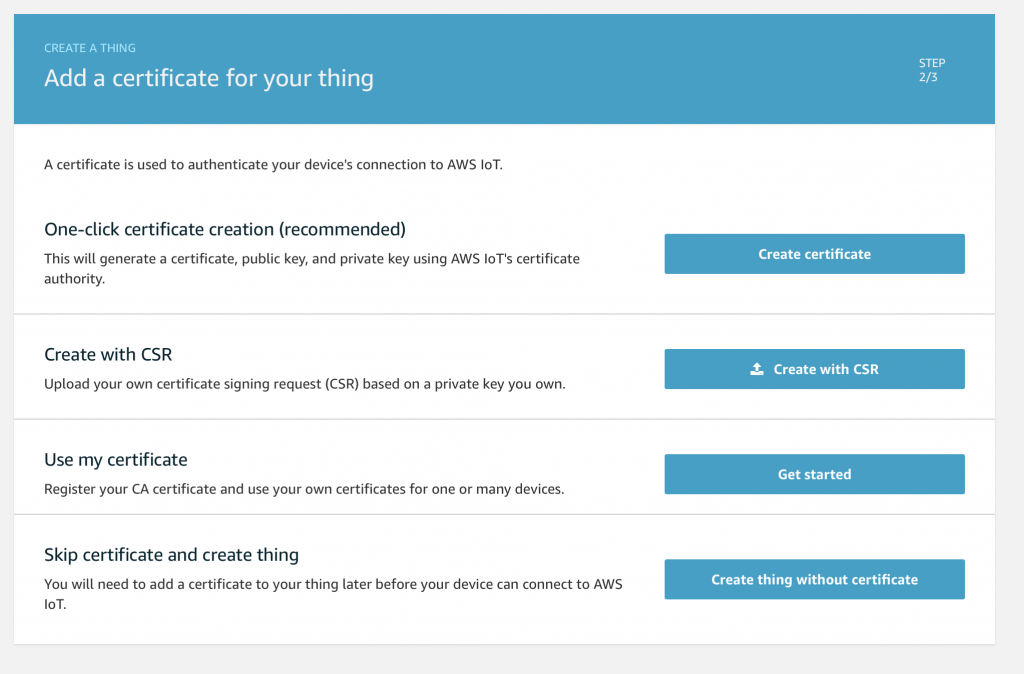
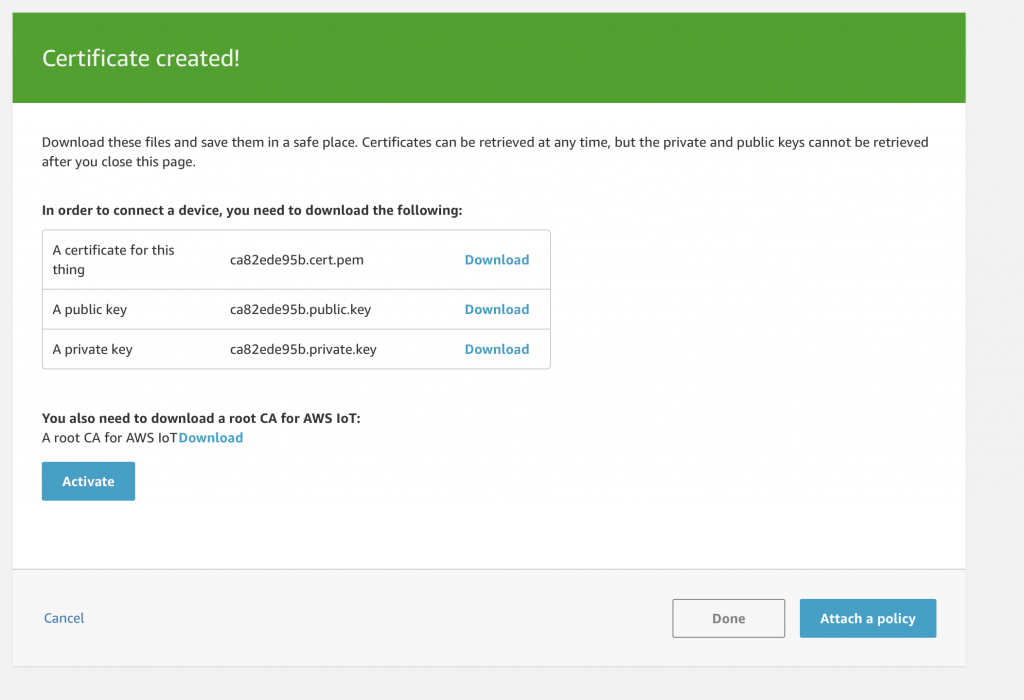
AnyCloud Bluetooth Advertising Scanner (Part 3)
Adding Observing functionality to the project
AnyCloud Bluetooth Utilities Library
A set of APIs for enhancement of the AnyCloud Library
AnyCloud Bluetooth Advertising Scanner (Part 4)
Adding a command line to the scanner
AnyCloud Bluetooth Advertising Scanner (Part 5)
Adding a history database to the scanner
AnyCloud Bluetooth Advertising Scanner (Part 6)
Decoding advertising packets
AnyCloud Bluetooth Advertising Scanner (Part 7)
Adding recording commands to the command line
AnyCloud Bluetooth Advertising Scanner (Part 8)
Adding filtering to the scanner
AnyCloud Bluetooth Advertising Scanner (Part 9)
Improve the print and add packet age
AnyCloud Bluetooth Advertising Scanner (Part 10)
Sort the database
All of the code can be found at git@github.com:iotexpert/AnyCloudBLEScanner.git and https://github.com/iotexpert/AnyCloudBLEScanner.git
There are git tags in place starting at part 5 so that you can look at just that version of the code. "git tag" to list the tags. And "git checkout part6" to look at the part 6 version of the code.
You can also create a new project with this is a template if you have the IoT Expert Manifest Files installed
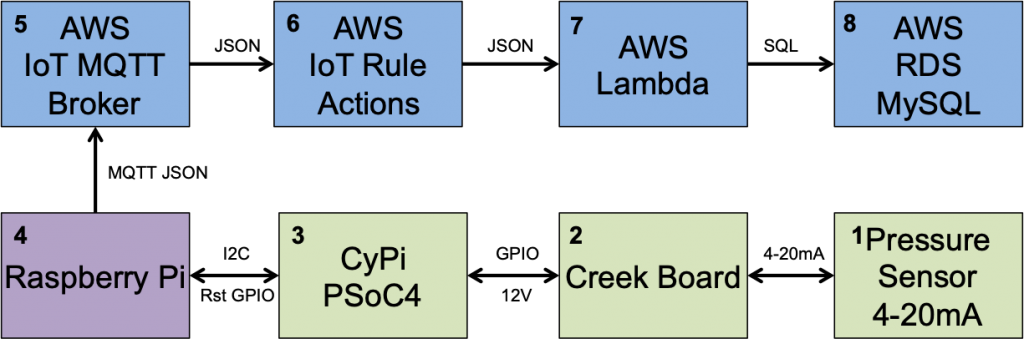
Bluetooth Application Architecture
Bluetooth applications are divided into these four pieces
- You user application which responds to events and sends messages from/to the Bluetooth host stack
- A Bluetooth Host Stack
- A Bluetooth Controller Stack
- The Bluetooth Radio
These four pieces can be divided into multiple chips, as few as one or as many as four. However, for this article, the project will be built to run on a PSoC 6 + CYW43012 WiFi/Bluetooth Combo chip. Specifically:
- My scanner application running on the PSoC 6
- The Bluetooth Host Stack running on the PSoC 6
- The BlueTooth Controller Firmware running on the CYW43012
- A Bluetooth Radio on the CYW43012
But how do they talk? Simple, there is:
- A UART Host Controller Interface (HCI) between the two chips
- A GPIO to serve as a deep sleep wakeup from the 43012 –> PSoC 6
- A GPIO to serve as the bluetooth controller wakeup from the PSoC 6 –> 43012
- A GPIO to turn on the Bluetooth regulator from the PSoC 6 –> 43012
Here is the block diagram from the CY8CKIT-062S2-43012 Kit Guide. Notice that signals labeled UART and Control going between the PSoC 6 and the CYW43012.
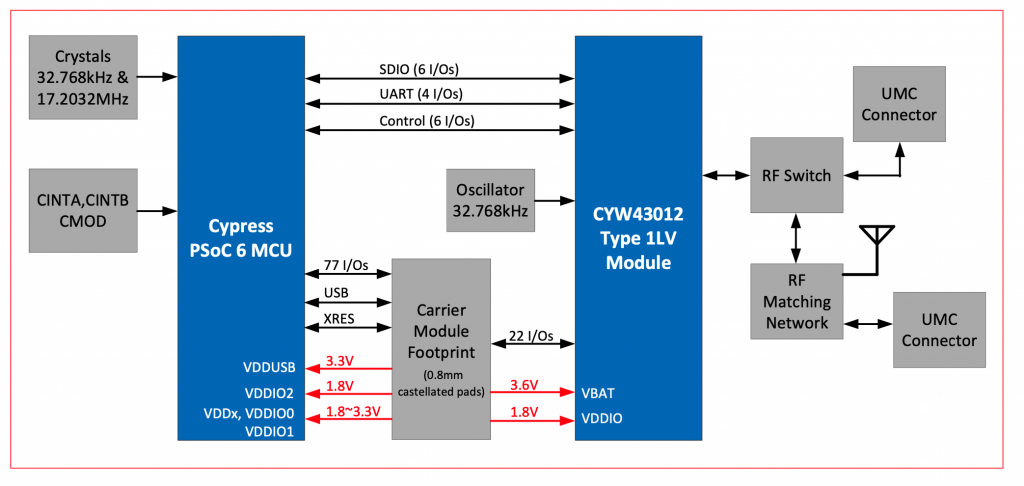
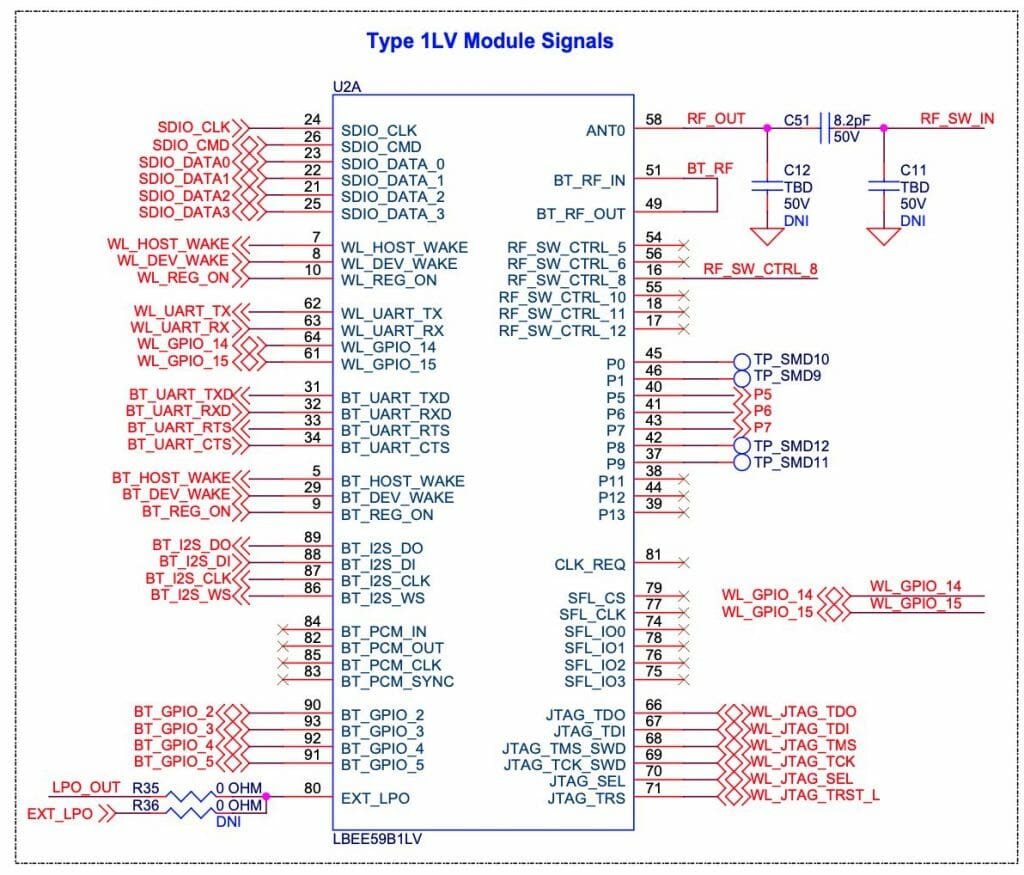
And when you read more deeply into the schematic you can see the signals labeled
- BT_UART_TXD/RXD/CTS/RTS
- BT_HOST_WAKE
- BT_DEV_WAKE
- BT_REG_ON
How to Start the AnyCloud Bluetooth Stack
To actually start the AnyCloud Bluetooth stack you will call two functions
- cybt_platform_config_init – that will setup the hardware interface to the CYW43012
- wiced_bt_stack_init that will:
- Start a task to manage the Host Controller Interface
- Download the controller firmware to the CYW43012
- Start a task to manage the host stack
- Initialize both the host and the controller
- Call you back when that is all done
Here is an example from main.
cybt_platform_config_init(&bt_platform_cfg_settings);
wiced_bt_stack_init (app_bt_management_callback, &wiced_bt_cfg_settings);
When you look at these two function calls, you will find that you need to provide three things:
- A platform hardware configuration structure called bt_platform_cfg_settings
- The Bluetooth stack configuration settings structure called wiced_bt_cfg_settings
- A management callback called app_bt_management_callback
bt_platform_cfg_settings
The purpose of the hardware configuration structure is to define the UART + parameters and the wakeup GPIOs. Specifically, the hardware configuration structure defines the configuration of the host controller interface (hci)
- The HCI transport scheme (in this case UART)
- The pins of the UART
- Baud Rate
- Data Bits
- Stop Bits
- Parity
- Flow Control
And the controller low power behavior (in the .controller_config member)
This is a fairly standard configuration and I think that we should help you by providing this structure somewhere in the BSP. But for now, you need to provide it (in an upcoming article I’ll update the IoT Expert Bluetooth Library to provide it). Here is the specific structure that I will be using.
const cybt_platform_config_t bt_platform_cfg_settings =
{
.hci_config =
{
.hci_transport = CYBT_HCI_UART,
.hci =
{
.hci_uart =
{
.uart_tx_pin = CYBSP_BT_UART_TX,
.uart_rx_pin = CYBSP_BT_UART_RX,
.uart_rts_pin = CYBSP_BT_UART_RTS,
.uart_cts_pin = CYBSP_BT_UART_CTS,
.baud_rate_for_fw_download = 115200,
.baud_rate_for_feature = 115200,
.data_bits = 8,
.stop_bits = 1,
.parity = CYHAL_UART_PARITY_NONE,
.flow_control = WICED_TRUE
}
}
},
.controller_config =
{
.bt_power_pin = CYBSP_BT_POWER,
.sleep_mode =
{
#if (bt_0_power_0_ENABLED == 1) /* BT Power control is enabled in the LPA */
#if (CYCFG_BT_LP_ENABLED == 1) /* Low power is enabled in the LPA, use the LPA configuration */
.sleep_mode_enabled = true,
.device_wakeup_pin = CYCFG_BT_DEV_WAKE_GPIO,
.host_wakeup_pin = CYCFG_BT_HOST_WAKE_GPIO,
.device_wake_polarity = CYCFG_BT_DEV_WAKE_POLARITY,
.host_wake_polarity = CYCFG_BT_HOST_WAKE_IRQ_EVENT
#else /* Low power is disabled in the LPA, disable low power */
.sleep_mode_enabled = false
#endif
#else /* BT Power control is disabled in the LPA – default to BSP low power configuration */
.sleep_mode_enabled = true,
.device_wakeup_pin = CYBSP_BT_DEVICE_WAKE,
.host_wakeup_pin = CYBSP_BT_HOST_WAKE,
.device_wake_polarity = CYBT_WAKE_ACTIVE_LOW,
.host_wake_polarity = CYBT_WAKE_ACTIVE_LOW
#endif
}
},
.task_mem_pool_size = 2048
};
wiced_bt_cfg_settings
The Cypress WICED Bluetooth Stack has a boatload of configuration settings. When you call the stack start function you need to provide all of those settings in a structure of type “wiced_bt_cfg_settings_t” which is actually a structure of structures. There are several basic ways to set these settings
- Start from scratch and build you own settings
- Copy from an example project
- Use the Bluetooth Configurator to generate the structure
For the purposes of THIS project I started by copying the structure from on of the example projects and then modifying the three numbers that were relevant to me. Specifically
- max_simultanous_link – which I changed to 0 because this is simply a Bluetooth Observer
- low_duty_scan_interval – how long in the window to listen for advertising packets
- low_duty_scan_window – how wide the window of listening should be
const wiced_bt_cfg_settings_t wiced_bt_cfg_settings =
{
.device_name = (uint8_t *)BT_LOCAL_NAME, /**< Local device name (NULL terminated) */
.device_class = {0x00, 0x00, 0x00}, /**< Local device class */
.security_requirement_mask = BTM_SEC_NONE, /**< Security requirements mask (BTM_SEC_NONE, or combinination of BTM_SEC_IN_AUTHENTICATE, BTM_SEC_OUT_AUTHENTICATE, BTM_SEC_ENCRYPT (see #wiced_bt_sec_level_e)) */
.max_simultaneous_links = 0, /**< Maximum number simultaneous links to different devices */
.ble_scan_cfg = /* BLE scan settings */
{
.scan_mode = BTM_BLE_SCAN_MODE_PASSIVE, /**< BLE scan mode (BTM_BLE_SCAN_MODE_PASSIVE, BTM_BLE_SCAN_MODE_ACTIVE, or BTM_BLE_SCAN_MODE_NONE) */
/* Advertisement scan configuration */
.high_duty_scan_interval = WICED_BT_CFG_DEFAULT_HIGH_DUTY_SCAN_INTERVAL, /**< High duty scan interval */
.high_duty_scan_window = WICED_BT_CFG_DEFAULT_HIGH_DUTY_SCAN_WINDOW, /**< High duty scan window */
.high_duty_scan_duration = 0, /**< High duty scan duration in seconds (0 for infinite) */
.low_duty_scan_interval = 96, /**< Low duty scan interval */
.low_duty_scan_window = 96, /**< Low duty scan window */
.low_duty_scan_duration = 0, /**< Low duty scan duration in seconds (0 for infinite) */
/* Connection scan configuration */
.high_duty_conn_scan_interval = WICED_BT_CFG_DEFAULT_HIGH_DUTY_CONN_SCAN_INTERVAL, /**< High duty cycle connection scan interval */
.high_duty_conn_scan_window = WICED_BT_CFG_DEFAULT_HIGH_DUTY_CONN_SCAN_WINDOW, /**< High duty cycle connection scan window */
.high_duty_conn_duration = 0, /**< High duty cycle connection duration in seconds (0 for infinite) */
.low_duty_conn_scan_interval = WICED_BT_CFG_DEFAULT_LOW_DUTY_CONN_SCAN_INTERVAL, /**< Low duty cycle connection scan interval */
.low_duty_conn_scan_window = WICED_BT_CFG_DEFAULT_LOW_DUTY_CONN_SCAN_WINDOW, /**< Low duty cycle connection scan window */
.low_duty_conn_duration = 0, /**< Low duty cycle connection duration in seconds (0 for infinite) */
/* Connection configuration */
.conn_min_interval = WICED_BT_CFG_DEFAULT_CONN_MIN_INTERVAL, /**< Minimum connection interval */
.conn_max_interval = WICED_BT_CFG_DEFAULT_CONN_MAX_INTERVAL, /**< Maximum connection interval */
.conn_latency = WICED_BT_CFG_DEFAULT_CONN_LATENCY, /**< Connection latency */
.conn_supervision_timeout = WICED_BT_CFG_DEFAULT_CONN_SUPERVISION_TIMEOUT, /**< Connection link supervision timeout */
},
.default_ble_power_level = 12 /**< Default LE power level, Refer lm_TxPwrTable table for the power range */
};
app_bt_management_callback
The last thing that you need to provide is a management callback. This function is called by the Bluetooth Stack when a “management event” occurs. There is a big-long-list of enumerated events of type wiced_bt_management_event_t. The events include things like the the stack started “BTM_ENABLED_EVENT”. Each event may have data associated with the event which is passed to you in a pointer to wiced_bt_management_event_data_t.
You typically deal with these events with a giant switch statement like this:
wiced_result_t app_bt_management_callback(wiced_bt_management_evt_t event, wiced_bt_management_evt_data_t *p_event_data)
{
wiced_result_t result = WICED_BT_SUCCESS;
switch (event)
{
case BTM_ENABLED_EVT:
if (WICED_BT_SUCCESS == p_event_data->enabled.status)
{
printf("Stack Started Successfully\n");
}
break;
default:
printf("Unhandled Bluetooth Management Event: 0x%x %s\n", event, btutil_getBTEventName(event));
break;
}
return result;
}
Tasks
The Bluetooth stack on the PSoC6 is operated with two tasks. Specifically, when you call the wiced_bt_stack_init it will startup:
- CYBT_HCI_Task – a task that sends and receives HCI packets going to the Radio chip
- CY_BT_Task – a task that manages the Bluetooth Host Stack
Here is print of the task list from my project:
AnyCloud> tasks Name State Priority Stack Num ------------------------------------------ nt shell X 0 236 5 IDLE R 0 115 6 blink B 0 98 4 CYBT_BT_Task B 4 1371 2 sleep_task B 6 217 1 CYBT_HCI_Task B 5 950 3 Tmr Svc B 6 76 7 ‘B’ – Blocked ‘R’ – Ready ‘D’ – Deleted (waiting clean up) ‘S’ – Suspended, or Blocked without a timeout Stack = bytes free at highwater
Now with the background in place, in the next article I will discuss Bluetooth advertising and how to build the observer project.