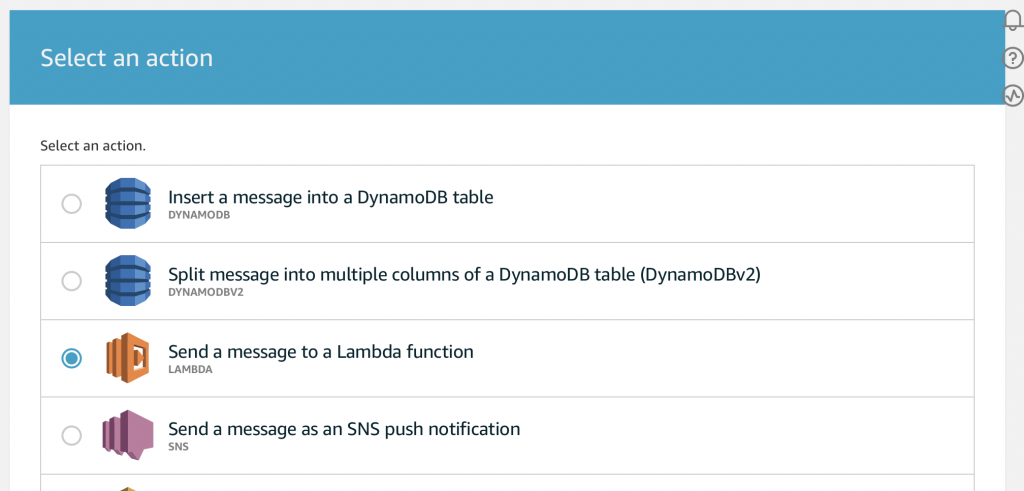
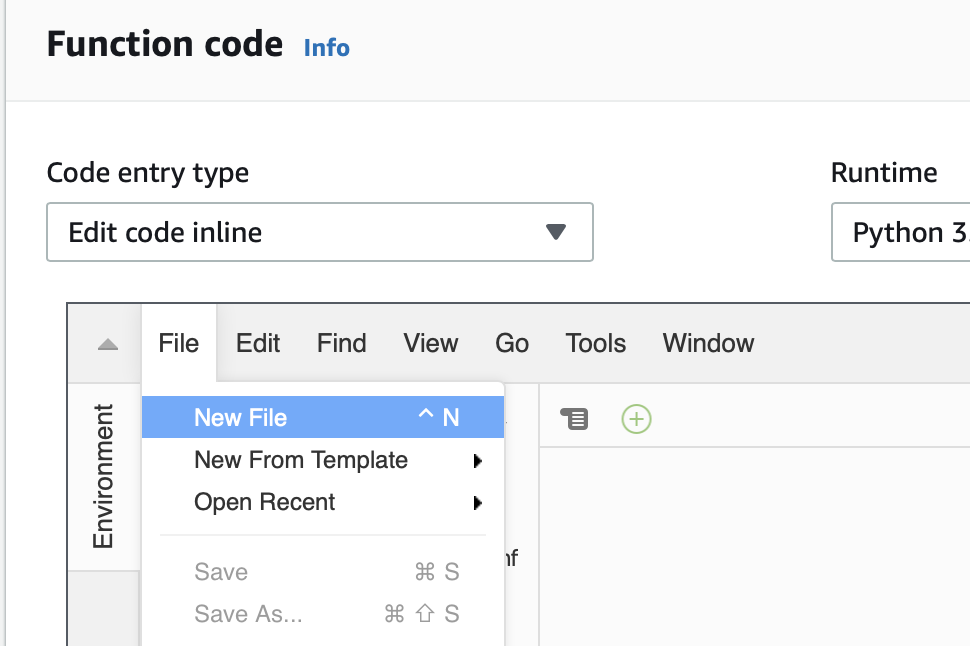
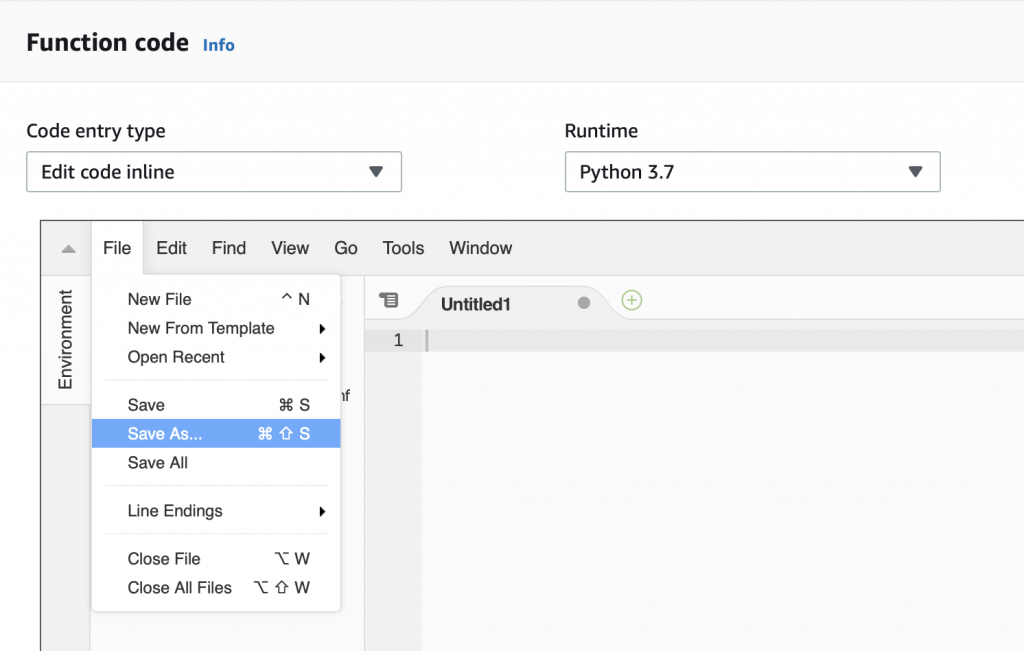
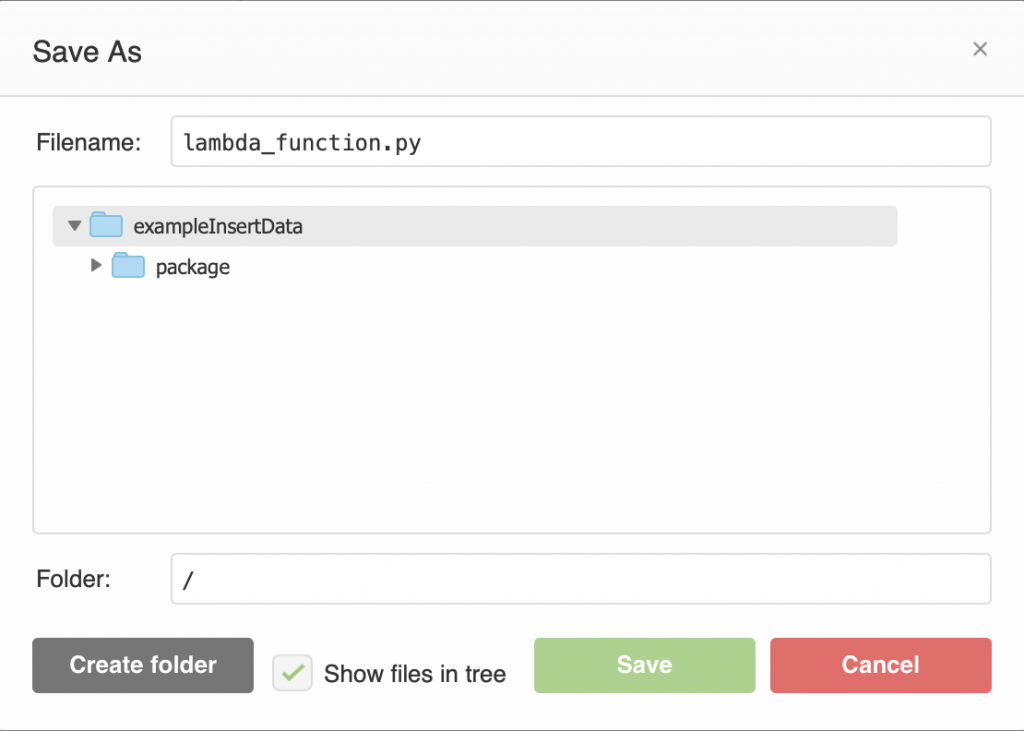
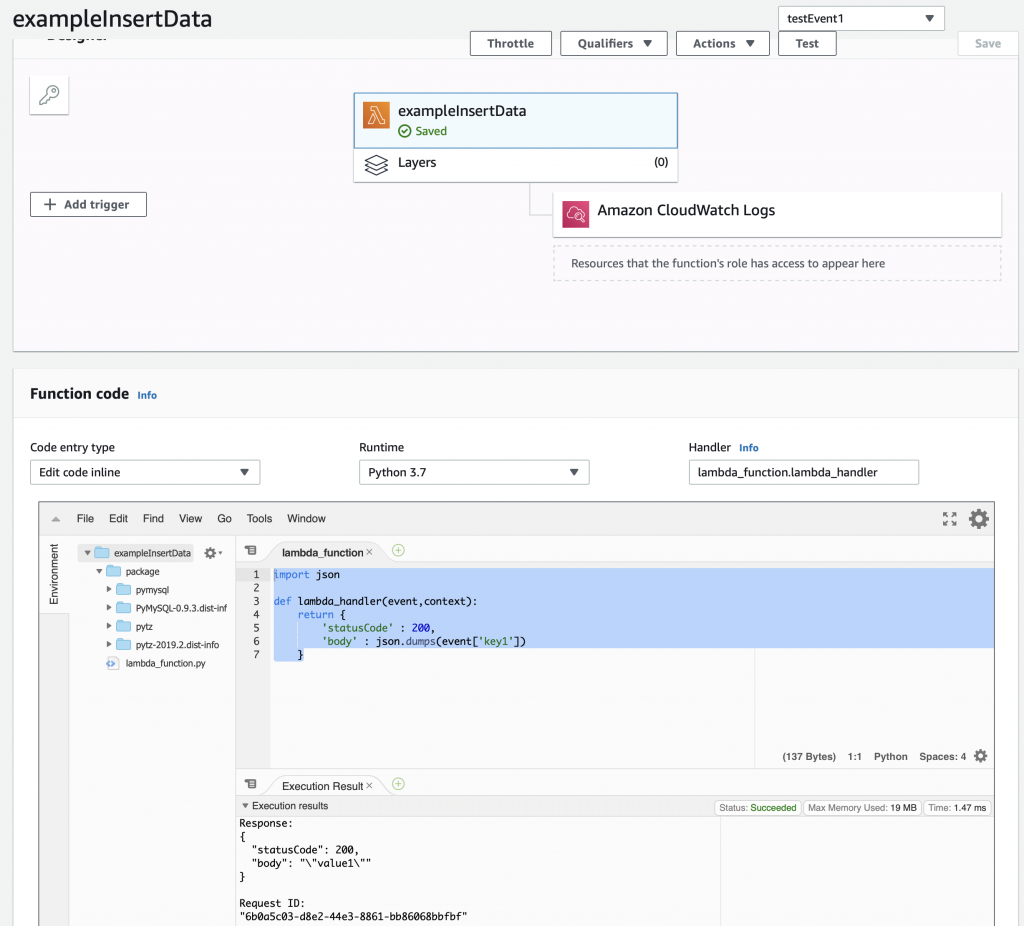
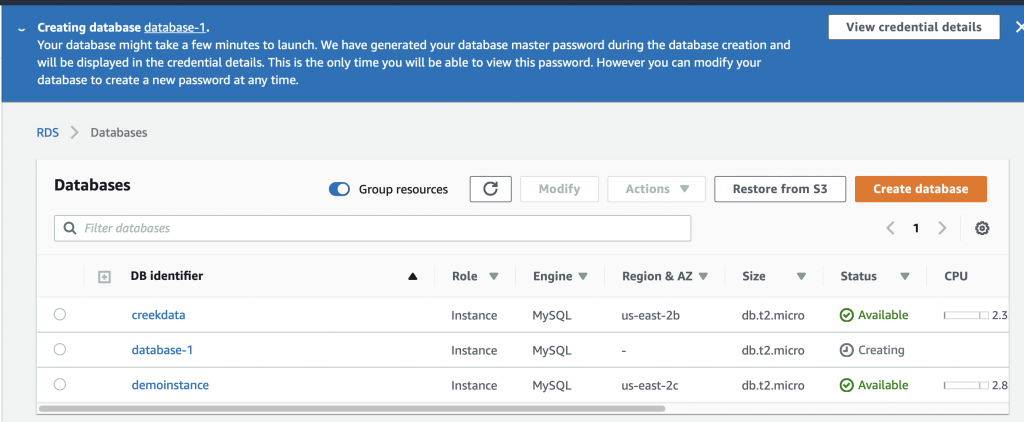
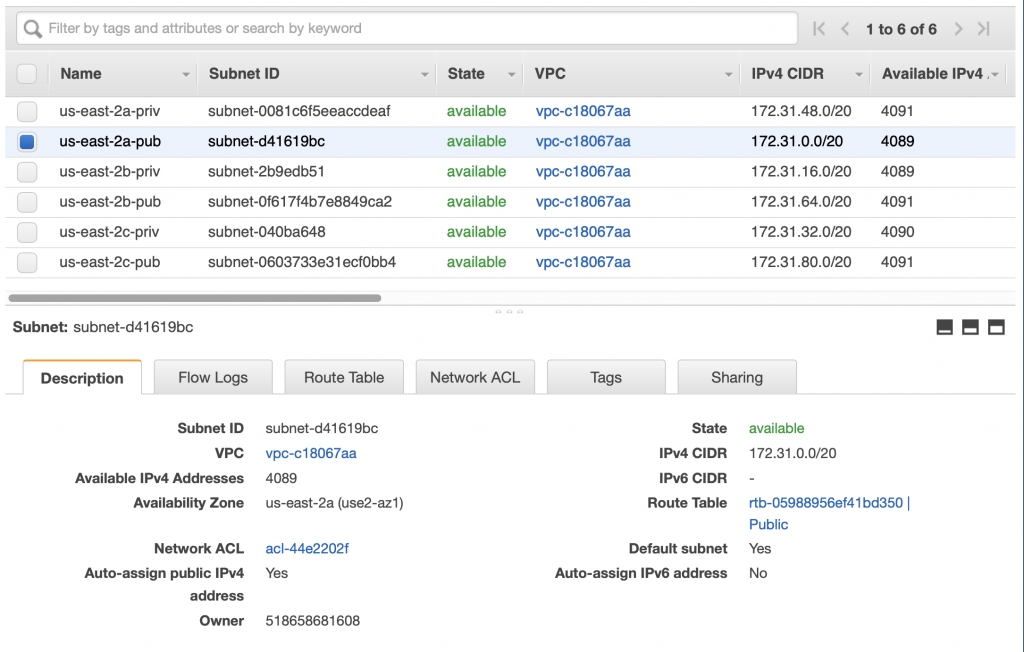
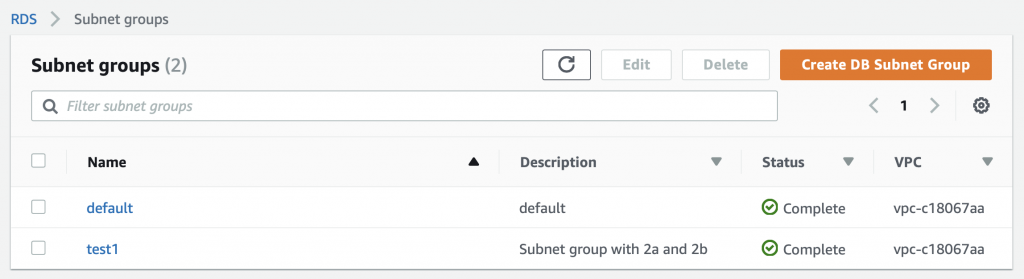
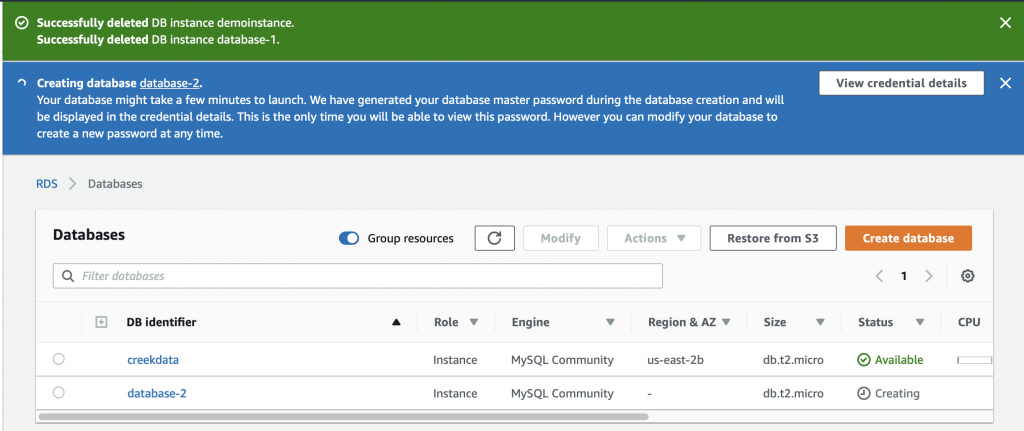
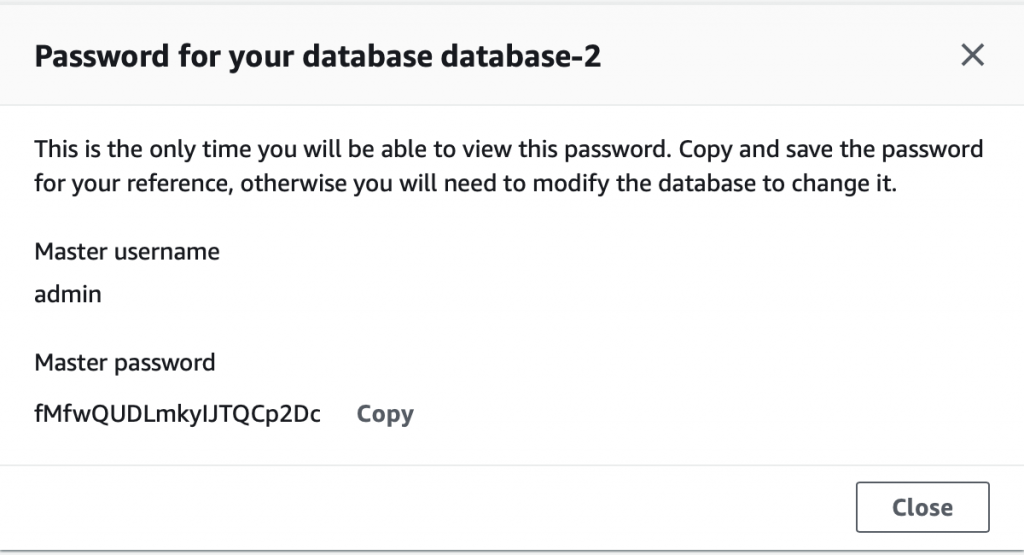
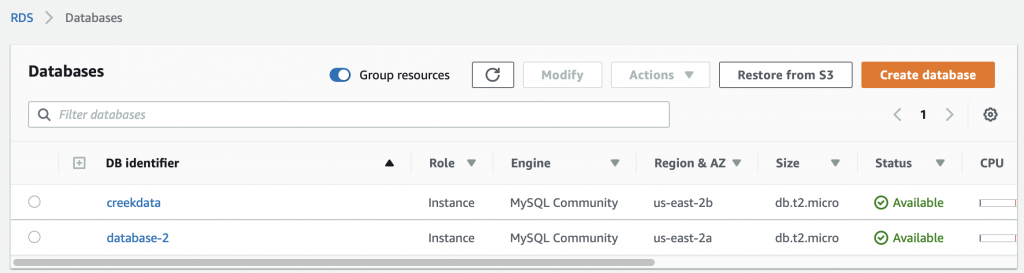
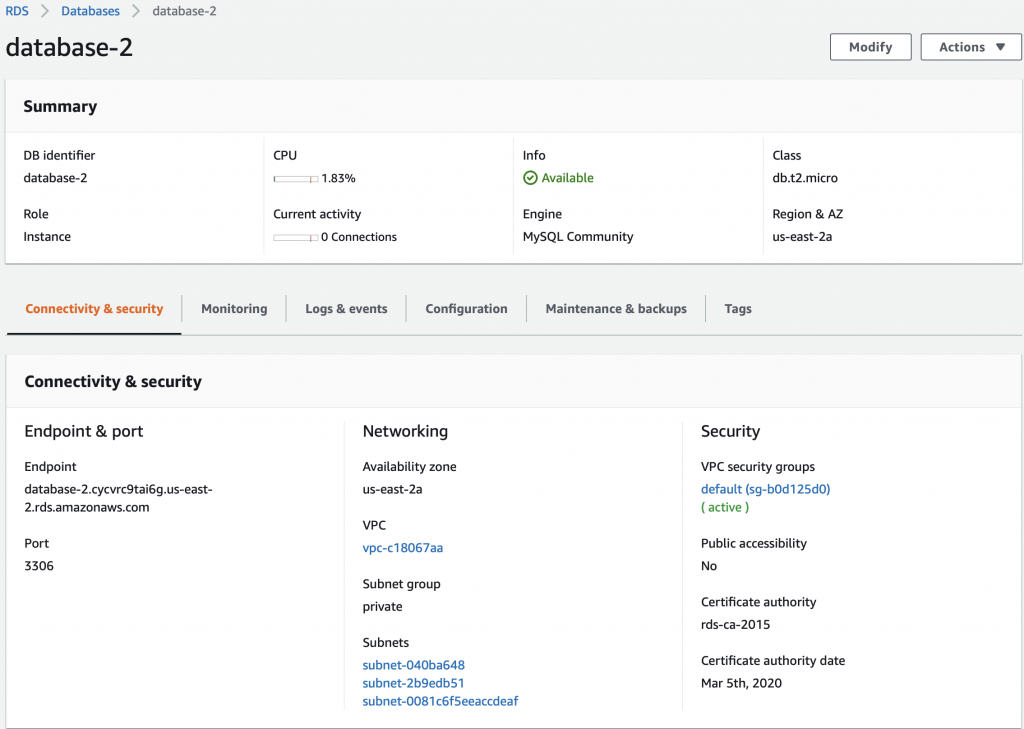
Summary
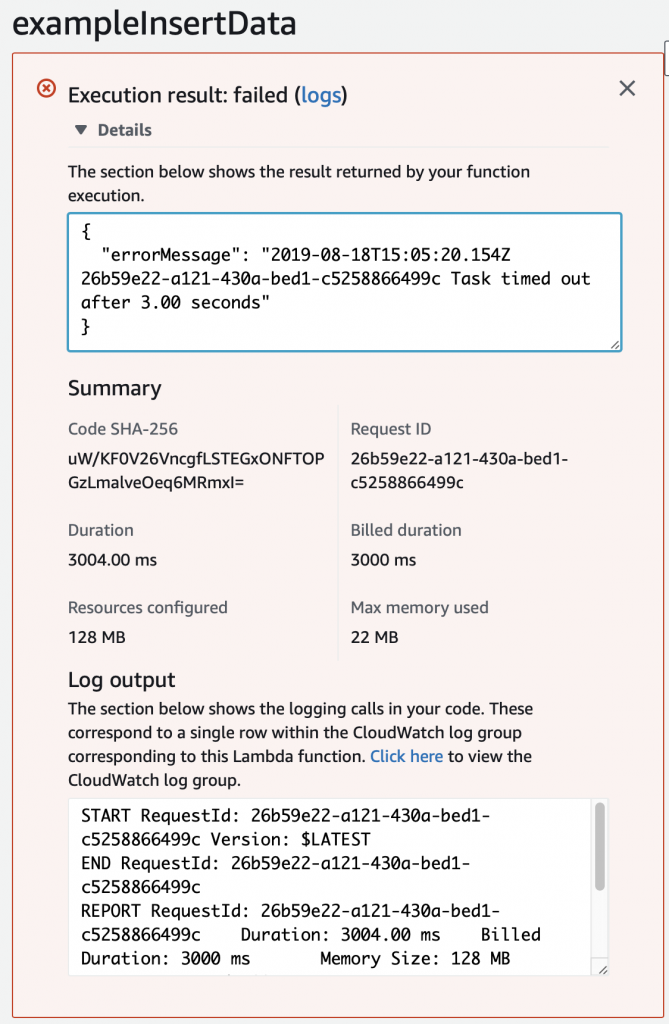
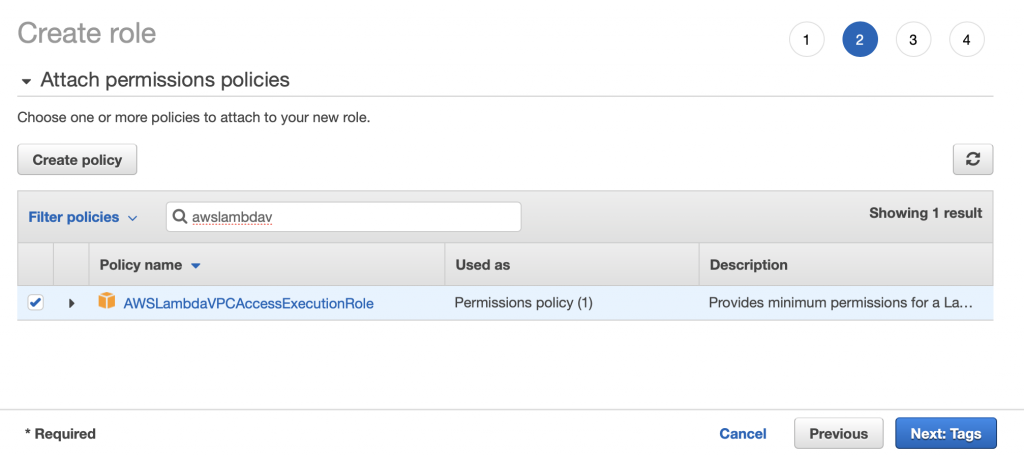
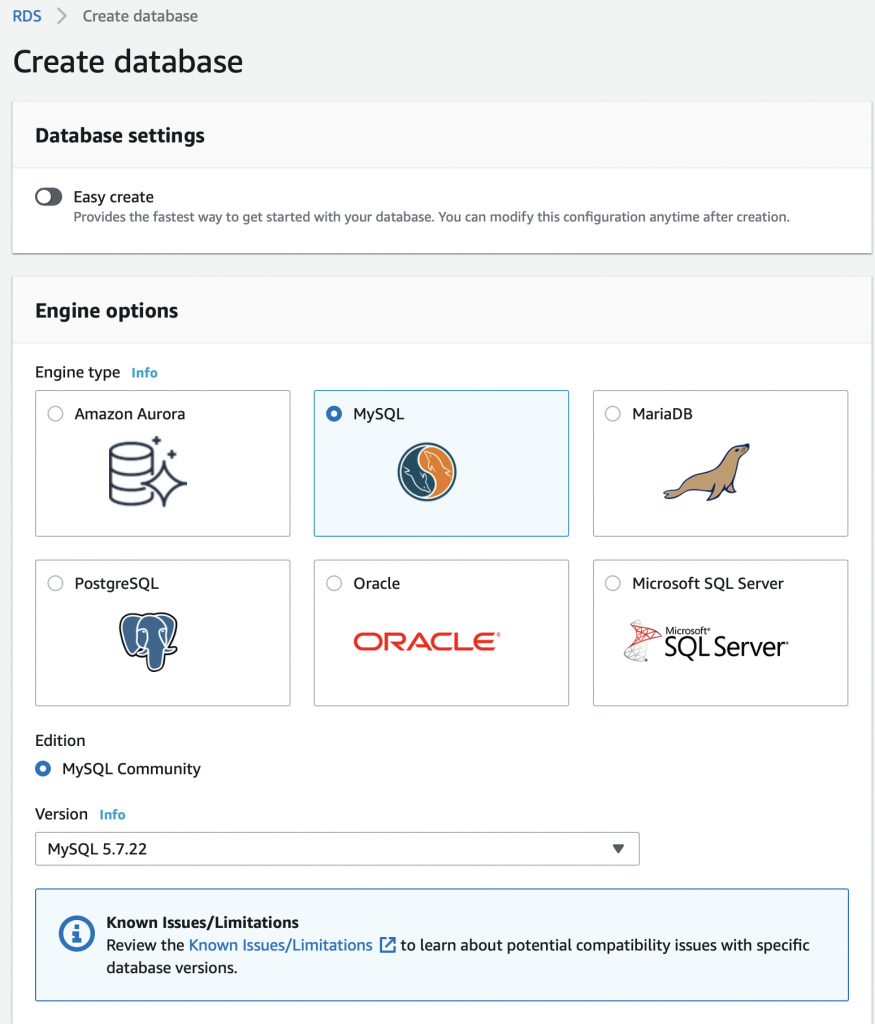
This article explains in detail how to use and debug SSD1306 displays. In this article, I use the Segger emWin library and MBEDOS, but for all practical purposes this discussion applies to all other interfaces to the board including Arduino, Raspberry Pi, Adafruit, etc. I will say from the outset that I spent far far too much time digging into the inner workings of an 11 year old graphics driver. Oh well, hopefully someone will get some benefit.
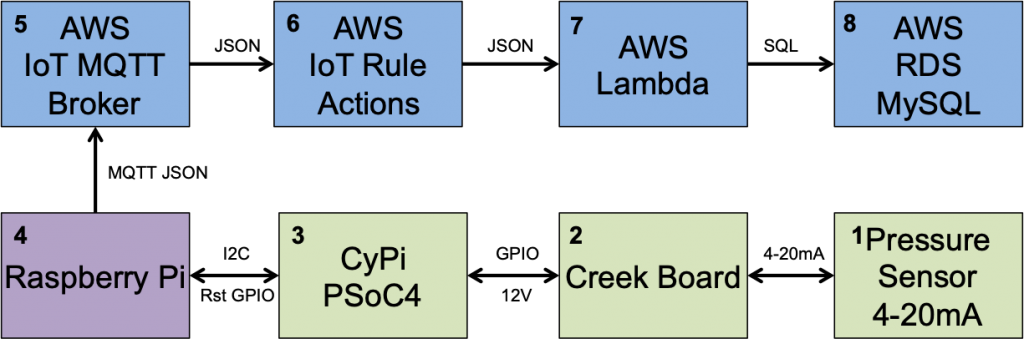
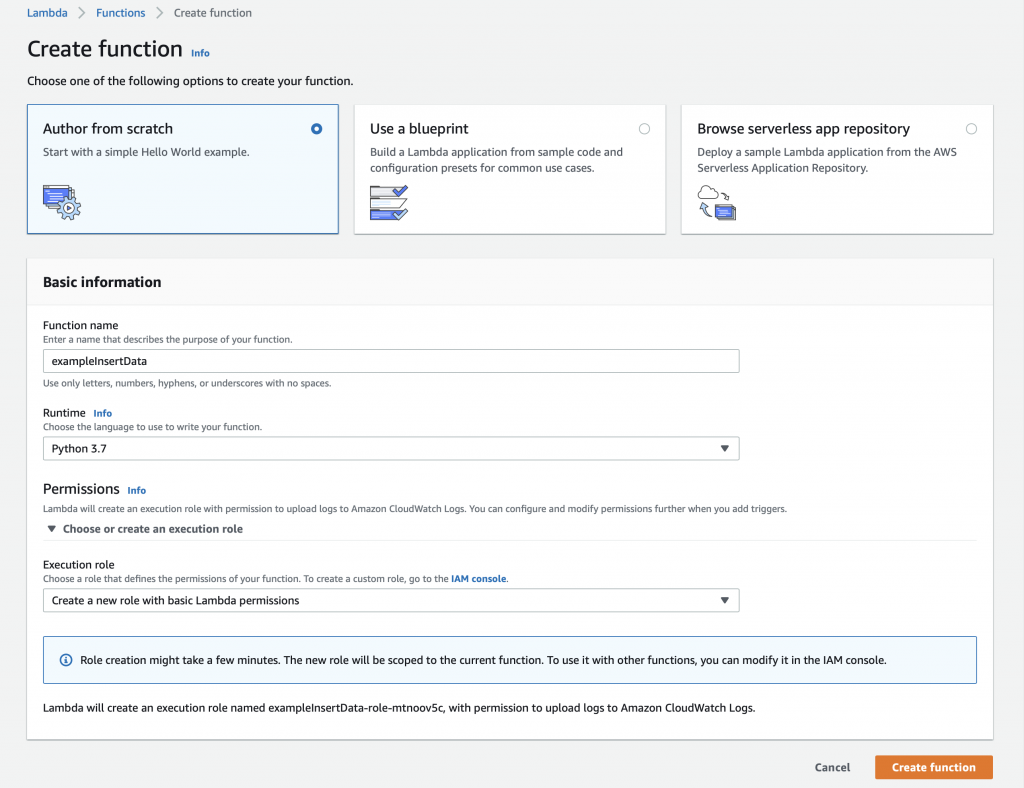
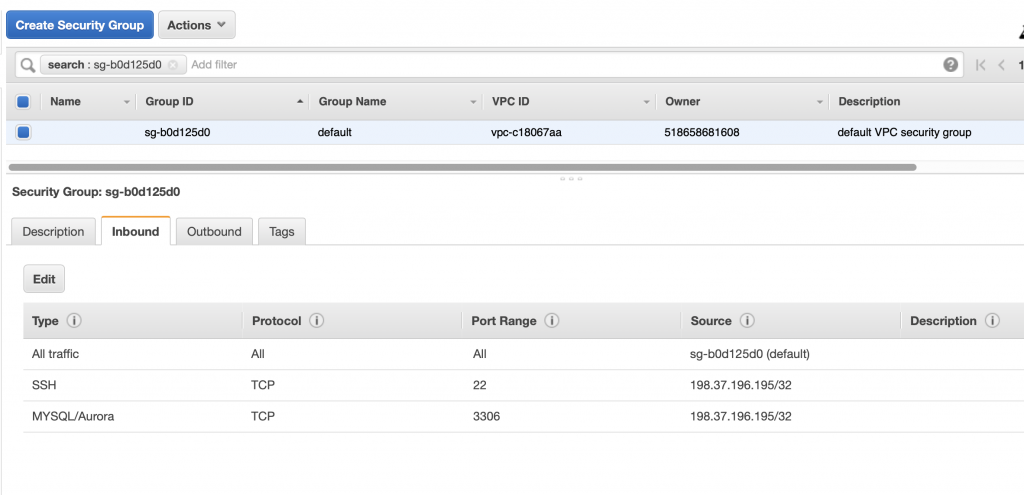
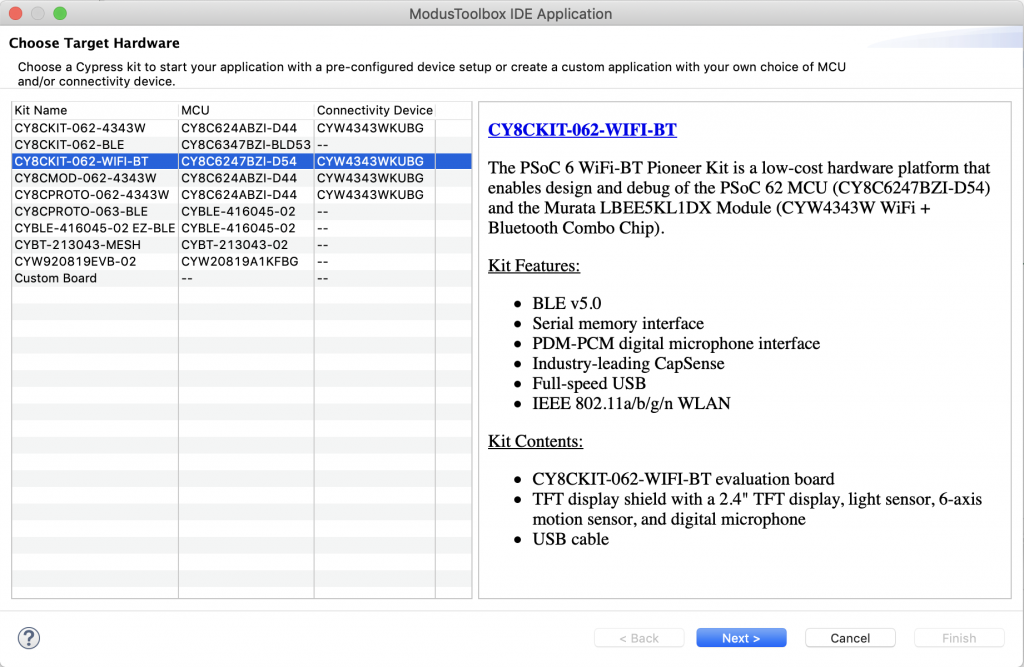
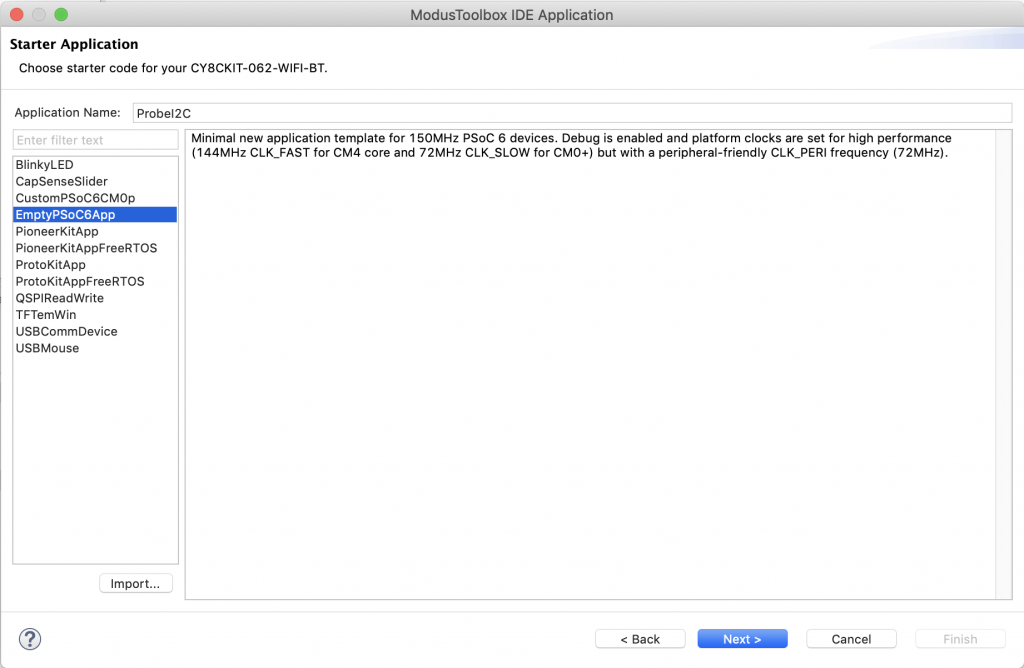
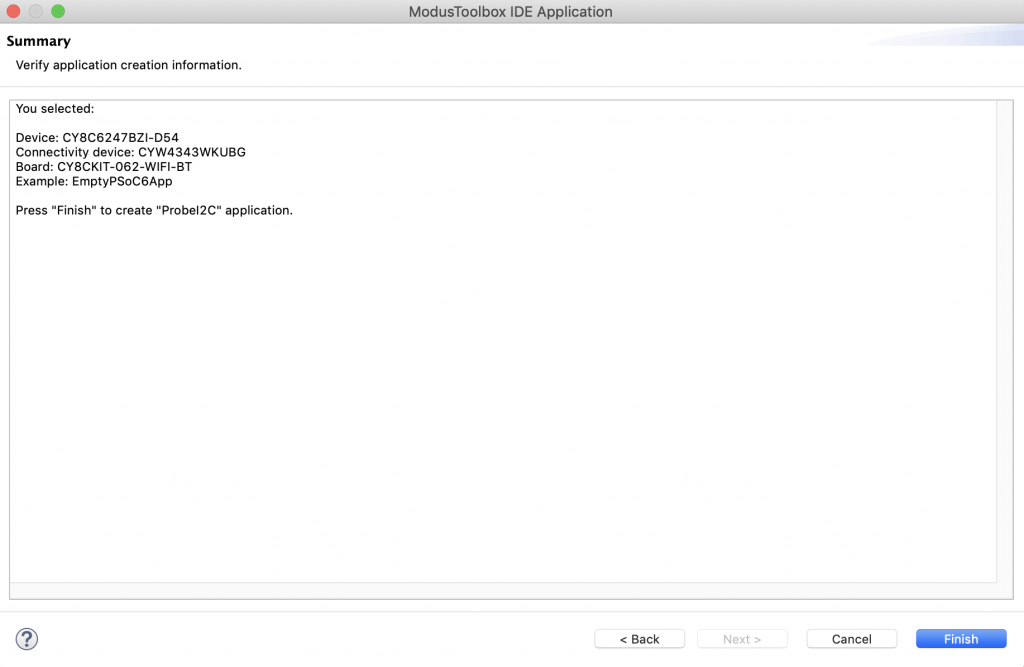
A year ago (or so) I designed a user interface board called the CY8CKIT-032 to go with my Cypress WICED WiFi book and class. This board uses a PSoC 4 Analog co-processor which can do a bunch of cool stuff. I have a series of articles planned about that board, but that will be for another day. One of the things that I did was put a 0.96″ I2C OLED Display based on a SSD1306 driver on the board. These displays are widely available from Alibaba and eBay for <$2. I think that the displays are being used in inexpensive cells phones in China so there are tons of them and they are CHEAP! The bad news is that if you google “ssd1306 problems” you will find an absolute rogues gallery of unpleasantness. It seems that tons of people struggle to get these things working.

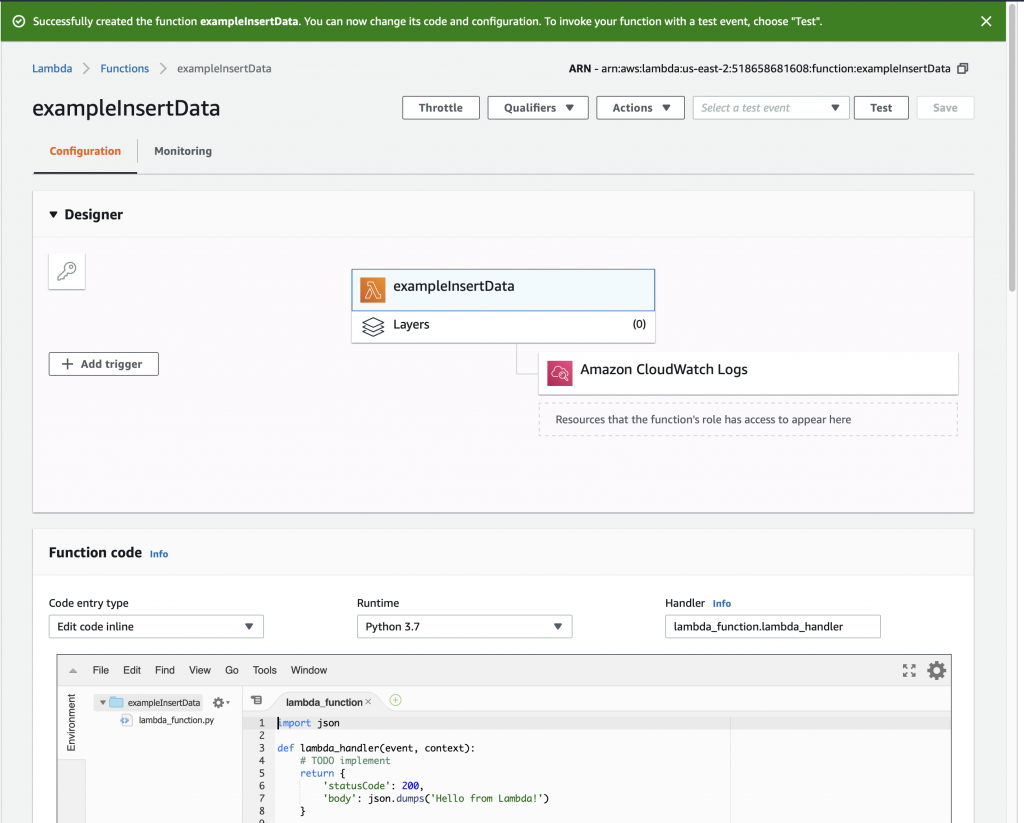
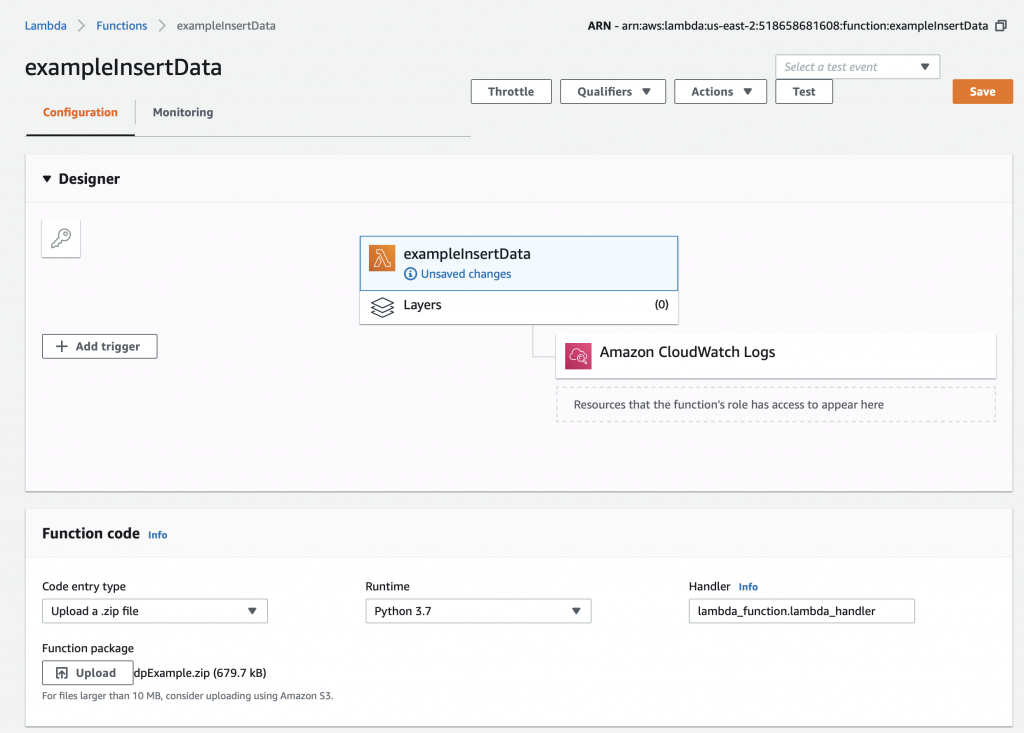
This whole thing started last week as Cypress released and update to our MBED OS implementation. This update included releasing a complete set of the Segger emWin drivers. I had been wanting to step up to a more robust graphics library than the Adafruit library that I used in this article. I was pleased to see that our release included the emWin SPAGE driver which knows how to talk to a bunch of different page based displays including the SSD1306.
But, as always, I had to wrestle with the display a little bit before I got everything working. This time I wrote down what I did/learned. So, for this article I will describe
- The SSD1306 Electrical Interface
- The SSD1306 Software Interface
- The SSD1306 Driver Registers
- The SSD1306 Graphics Data RAM
- Reading from the Frame Buffer
- My Initialization Sequence
- Some Other Initialization Sequences
- A Bunch of Screen Problems & How To Fix
The Electrical Interface
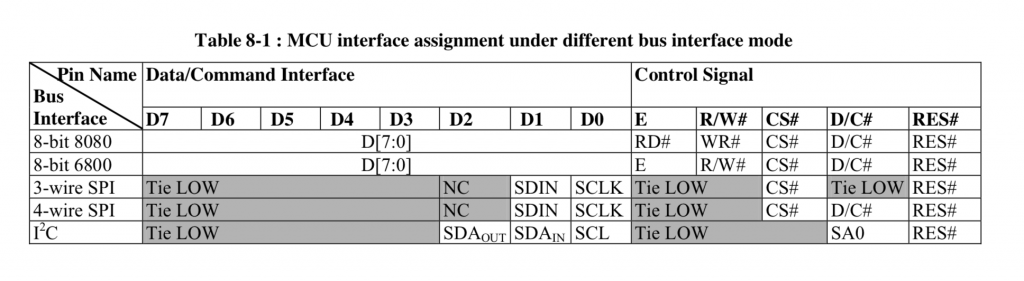
There is not a lot to know about the electrical interface. The data sheet specifies that the device can use I2C, SPI, 6800 and 8080. I have not seen either the 6800 or 8080 interface put onto any of these OLED displays. Like all driver chips, the SSD1306 has an absolute boatload of pins, in fact, 281. The chip is long and skinny and was made to be mounted either on the display under the glass or on the flex connector. Of the 281 pins, 128+64=196 are connected to the segments and commons in the display. The rest of the pins are either capacitors, no-connects, power/ground or data signals. The data signals are
- D0-D7 either parallel data for 8080/6800 or SDA/SCL for I2C or MOSI/MISO for SPI
- E – enable signal for 6800 or RD for 8080
- R/W# – Read Write for 6800/8080
- CS – Chip Select for SPI, 8080, 6800
- D/C# – Data or Command for SPI, 6800, 8080 or Slave Address Select for I2C
- Reset – Chip reset
For the I2C configurations it is common to tie the reset pin High and not bring the pin to a connector. The SA0 is also typically connected via a 0-ohm resistor to either 0 or 1 which configures the device to have the 7-bit address 0x3C or 0x3D or 8-bit 0x78 or 0x7A. Here is a picture of the back of one of my boards where you can see the 0ohm resistor.

Sometimes all of the data pins are available on the back of the board. This lets you move/add/change the 0-ohm resistors to configure the mode of the chip.


One thing you should be careful about is the I2C connections. I looked around on eBay and Alibaba to find a few pictures of the I2C displays. You should notice that all three of these displays are I2C, but all three of them have a different position and ORDER of VCC/GND/SCL/SDL When we ordered displays from China to go onto the CY8CKIT-032 we found displays in the same BATCH that had different orders of the VCC/GND.



Here is a SPI version that has reset and data/command pin brought out.


The Software Interface
There are two parts to the software interface.
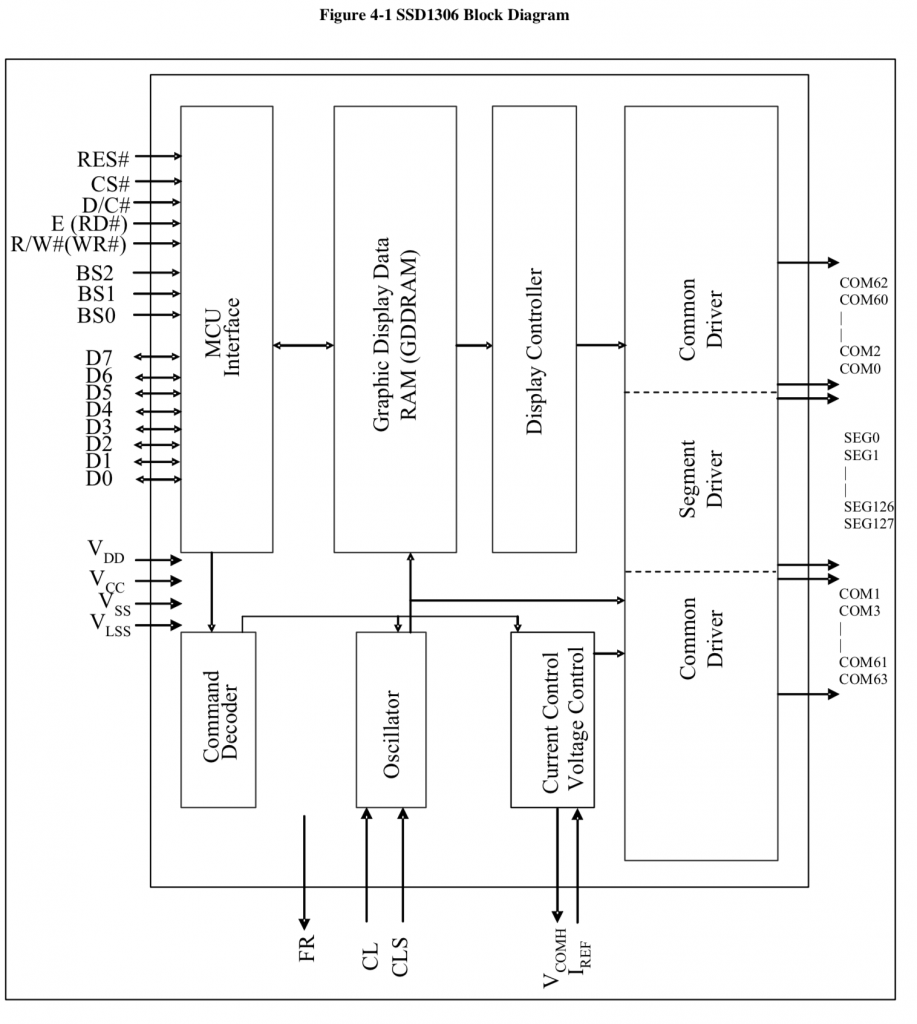
The first part is the command interface. Inside of the chip there are a bunch of logic circuits which which configure the charge pumps, sequence COMs and SEGs, charge and discharge capacitors etc. All of these things are configurable to allow for different configurations of screens e.g. different x-y sizes, configuration of what wires are connected to what places on the glass etc. Before you can get the display to work correctly you must initialize all of these values by sending commands. All the commands are 1-byte followed by 0 or more command parameters.
The second part is the data interface. Inside of the SSD1306 chip there is a Graphics Display DRAM – GDDRAM which has 1 bit for every pixel on the screen. The state machine inside of the chip called the Display Controller will loop through the bits one by one and display them on the correct place on the screen. This means that your MCU does not need to do anything to keep the display up to date. When you want a pixel lit up on the screen you just need to write the correct location in the GDDRAM.
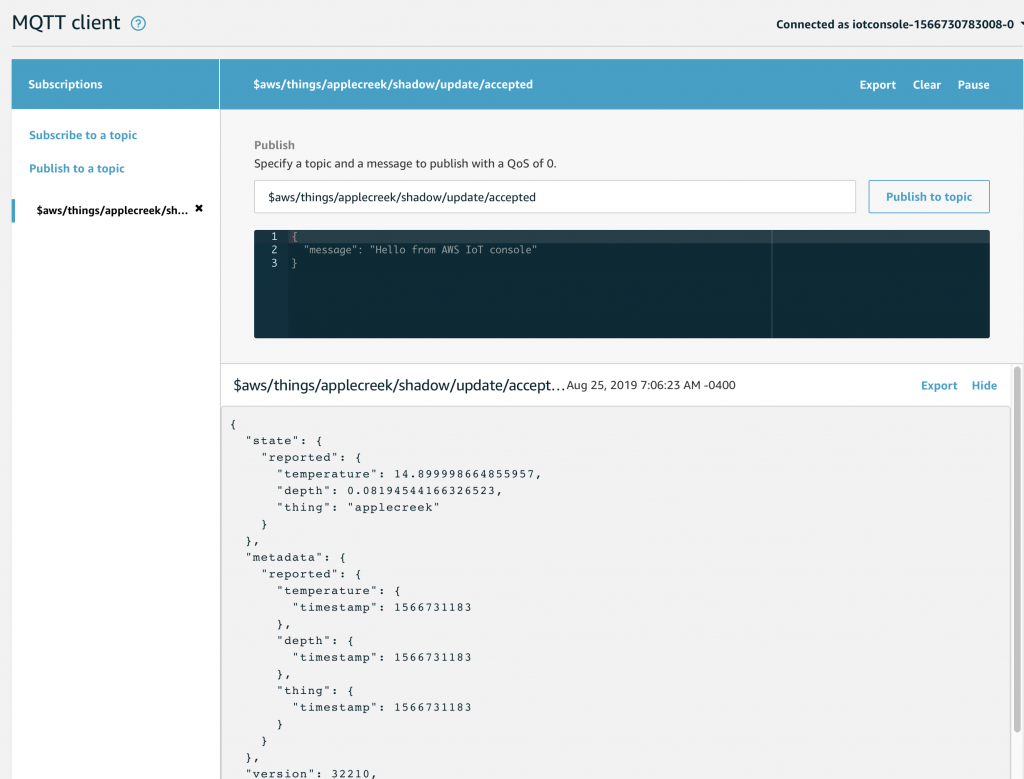
For the rest of this article I will focus on the serial interface, I2C. How do you send commands and data? Simple. When you start a transaction you send a control byte which tells the controller what to expect next. There are four legal control bytes.
- 0b10000000 = 0x80 = multiple commands
- 0b00000000 = 0x00 = one command
- 0b11000000 = 0xC0 = multiple data
- 0b01000000 = 0x40 = one data byte
Here is the picture from the datasheet (which I don’t find particularly illuminating) but it does describe the control byte.
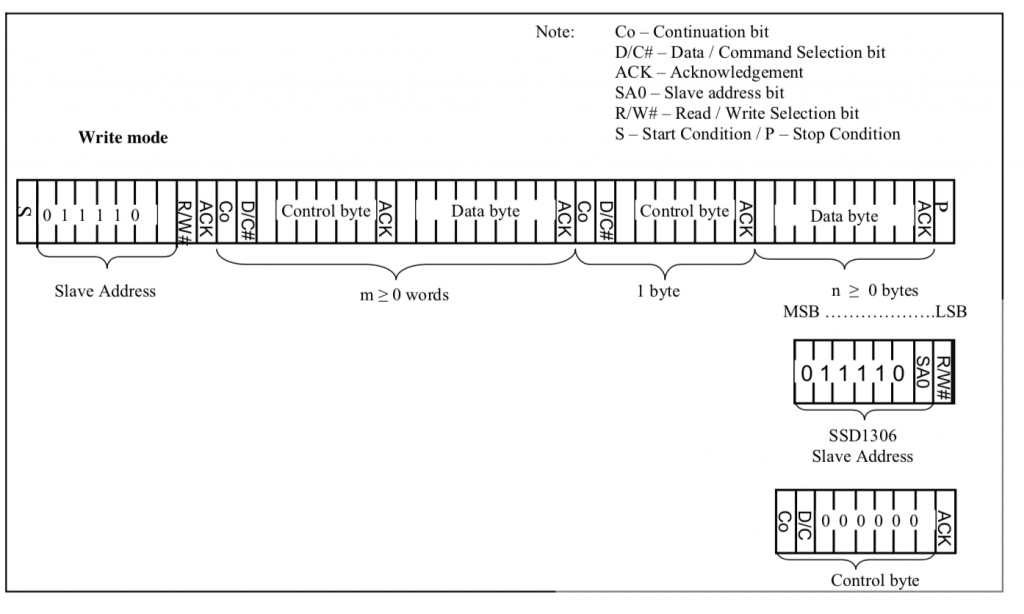
To send commands you write to the I2C bus with a control byte, then you send the command, then you send the optional parameters. If you want to send multiple commands you send the control byte 0x80, the command + parameters as many as you need.
The SSD1306 Driver Registers
In order for the driver chip to drive the screen you need to configure:
- How the driver is electrically connected to the OLED Screen
- What are the electrical parameters of the screen
- What are the electrical parameters of the system
- How you want to address the frame buffer
- The automatic scroll configuration settings
- The pixel data for the frame buffer, though it will happily display noise.
If you bought this screen from eBay, Adafruit, Alibaba etc. then you will get no say in 1-3, the electrical parameters of the system. Your screen will come prewired with all of the capacitors, OLED etc already attached to your driver commons and segments. If you didn’t buy the screen prepackaged, then it is highly unlikely you are reading this article. What this means is that you need to know the initializing sequence required to get the screen to work properly, then you just send the sequence down the wire from your MCU to the screen. From looking around on the internet, it appears to me that there in only one parameter that is different in any of the screens that I could find. Specifically the number of lines on the screen – either 32 or 64. Which means that all of these initialization implementations should really on have one difference register 0xA8 should be set to either n-1 aka 31 or 63
The other difference that you will see between different implementations is the memory address mode. In other words, how do you want to write data into the frame buffer from the MCU. Many of the open source graphics libraries use “Horizontal” mode. The Segger emWin library that I am using uses “Page” mode. More on this later.
When you look in the data sheet, unfortunately they mix and match the order of the information. However, from the data sheet, the categories are:
- Fundamental Commands
- Scrolling Commands
- Address Setting Commands
- Hardware Configuration
- Timing and Driving Scheme
- Charge Pump
I won’t put screen shots of the whole data sheet into this article, but I will show the command table and make a few clarifications on the text. Or at least I will clarify places where I got confused.
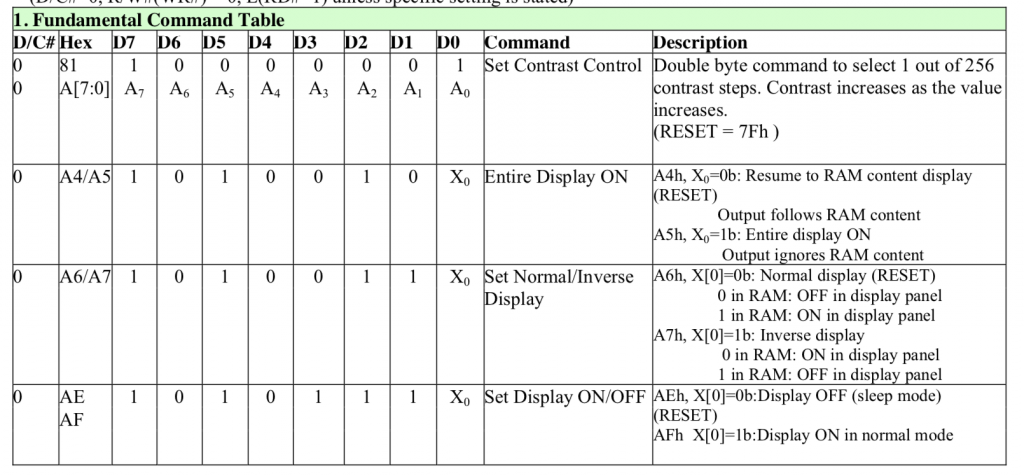
As to the fundamental commands. I tried a bunch of different contrast settings on my screens and could not tell the difference between them. I tried from 0x10 to 0xFF and they all looked the same to me. The best course of action is to use the default 0x7F. I don’t really know why there is a command 0xA5 “Entire Display ON ignore RAM”. The data sheet says “A5h command forces the entire display to be “ON”, regardless of the contents of the display data RAM”. I can’t think of a single use case for this. I suppose that if you issue 0xAE the screen will be all black… and if you issue 0xA5 the screen will be all white? But why?
And my definitions in the C driver file:
////////////////////////////////////////////////////////////////////////
// Fundamental Command Table Page 28
////////////////////////////////////////////////////////////////////////
#define OLED_SETCONTRAST 0x81
// 0x81 + 0-0xFF Contrast ... reset = 0x7F
// A4/A5 commands to resume displaying data
// A4 = Resume to RAM content display
// A5 = Ignore RAM content (but why?)
#define OLED_DISPLAYALLONRESUME 0xA4
#define OLED_DISPLAYALLONIGNORE 0xA5
// 0xA6/A7 Normal 1=white 0=black Inverse 0=white 1=black
#define OLED_DISPLAYNORMAL 0xA6
#define OLED_DISPLAYINVERT 0xA7
// 0xAE/AF are a pair to turn screen off/on
#define OLED_DISPLAYOFF 0xAE
#define OLED_DISPLAYON 0xAF
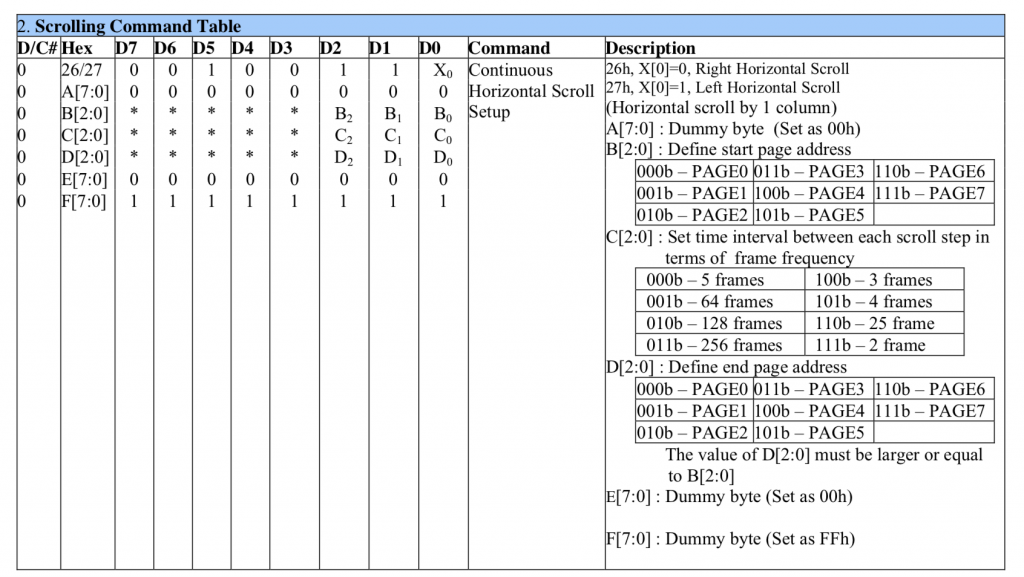
In the next section of the command table are the “Scrolling” commands. It appears that this graphics chip was setup to display text that is 8-pixels high. The scrolling commands will let you move the screen up/down and left/right to scroll automatically without having to update the the frame buffer. In other words it can efficiently scroll the screen without a bunch of load on your MCU CPU or on the data bus between them. The Adafruit graphics library provides the scrolling commands. However, I am not using them with the Segger Library.
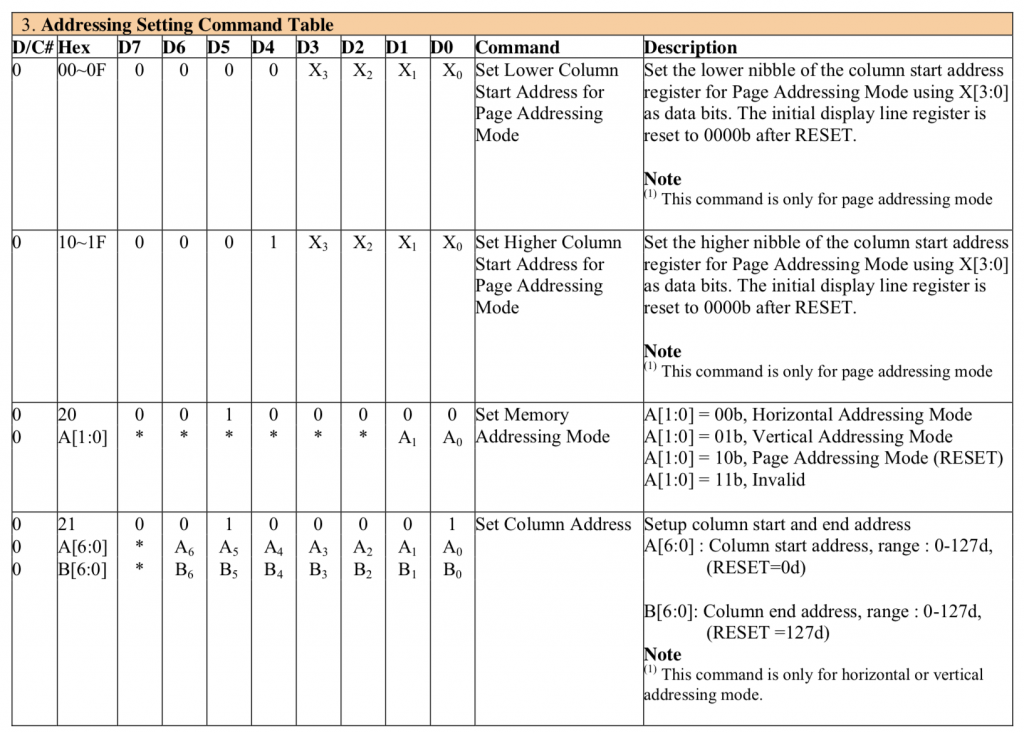
The next section has the commands to configure how your MCU writes data into the Graphics RAM aka the frame buffer. These commands fall into two categories. First the address mode. The address modes help you efficiently write the GDDRAM. When you send data to the frame buffer you really don’t want to send
- address, pixel, address, pixel, …
What you really would like to do is send
- Address, pixel, pixel, pixel … (and have the address be automatically incremented
At first blush you might think… why do I need a mode? Well there are some people who want the x address incremented… there are some people who want the y-address incremented and there are some people who want to have page address access. And what do you do when you get to the end of a line? or a column or a page? and what does the end mean?
The second set of commands in this table are the commands to set the starting address before you write data.
////////////////////////////////////////////////////////////////////////
// Address Setting Command Table
////////////////////////////////////////////////////////////////////////
// 00-0F - set lower nibble of page address
// 10-1F - set upper niddle of page address
#define OLED_SETMEMORYMODE 0x20
#define OLED_SETMEMORYMODE_HORIZONTAL 0x00
#define OLED_SETMEMORYMODE_VERTICAL 0x01
#define OLED_SETMEMORYMODE_PAGE 0x02
// 0x20 + 00 = horizontal, 01 = vertical 2= page >=3=illegal
// Only used for horizonal and vertical address modes
#define OLED_SETCOLUMNADDR 0x21
// 2 byte Parameter
// 0-127 column start address
// 0-127 column end address
#define OLED_SETPAGEADDR 0x22
// 2 byte parameter
// 0-7 page start address
// 0-7 page end Address
// 0xB0 -0xB7 ..... Pick page 0-7
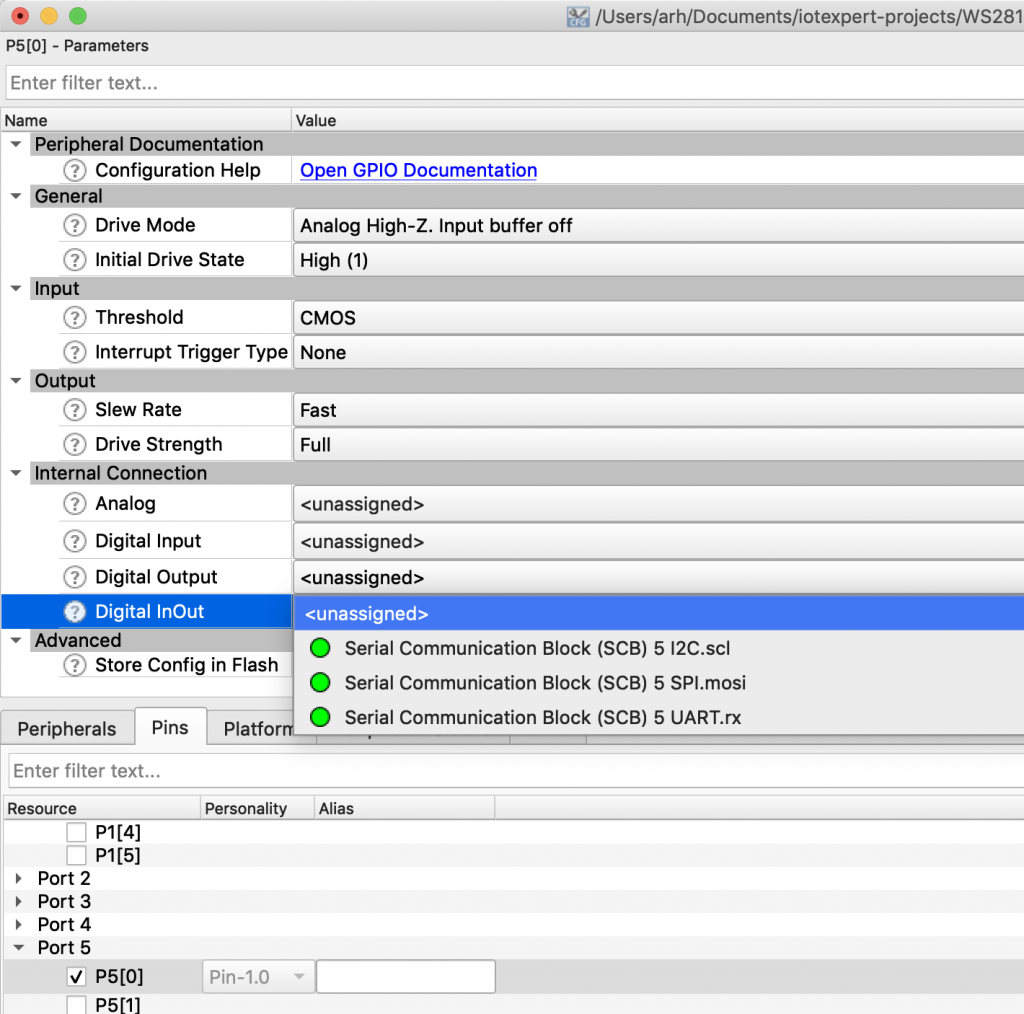
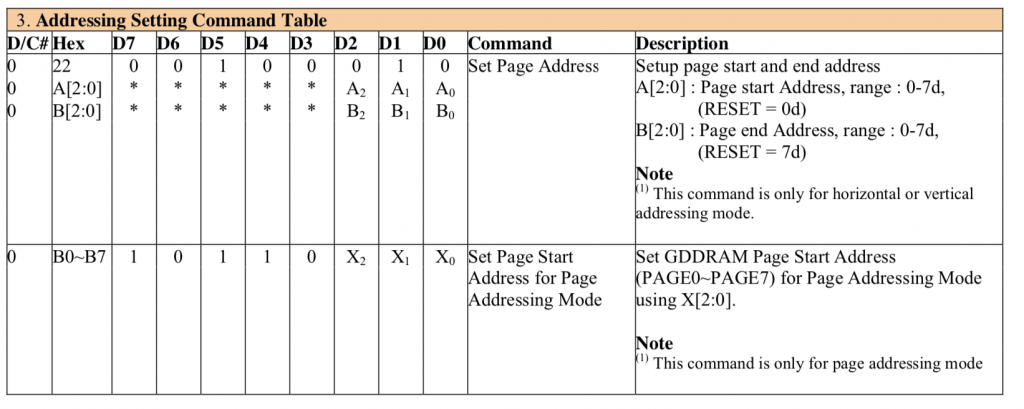
The hardware configuration registers allow the LED display maker to hookup the common and segment signals in an order that makes sense for the placement of the chip on the OLED glass. For a 128×64 display there are at least 196 wires, so the routing of these wires may be a total pain in the ass depending on the location of the chip. For instance the left and right might be swapped… or half the wires might come out on one side and the other half on the other side. These registers allow the board designer flexibility in making these connections. Commands 0xA0, 0xA1, 0xA8, 0xC0, 0xC8, 0xD3, 0xDa will all be fixed based on the layout. You have no control and they need to be set correctly or something crazy will come out.
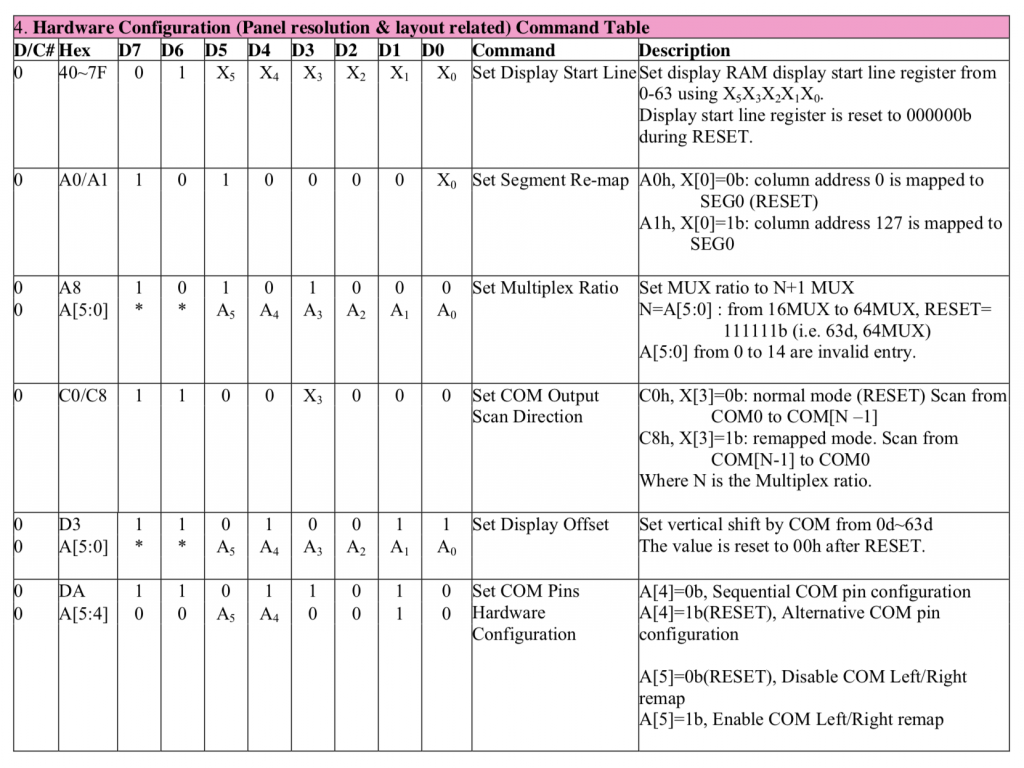
////////////////////////////////////////////////////////////////////////
// Hardware Configuration
////////////////////////////////////////////////////////////////////////
// 40-7F - set address startline from 0-127 (6-bits)
#define OLED_SETSTARTLINE_ZERO 0x40
// Y Direction
#define OLED_SEGREMAPNORMAL 0xA0
#define OLED_SEGREMAPINV 0xA1
#define OLED_SETMULTIPLEX 0xA8
// 0xA8, number of rows -1 ... e.g. 0xA8, 63
// X Direction
#define OLED_COMSCANINC 0xC0
#define OLED_COMSCANDEC 0xC8
// double byte with image wrap ...probably should be 0
#define OLED_SETDISPLAYOFFSET 0xD3
// Double Byte Hardware com pins configuration
#define OLED_SETCOMPINS 0xDA
// legal values 0x02, 0x12, 0x022, 0x032
The next sections of commands are part of the electrical configuration for the glass.
0xD5 essentially sets up the display update rate by 1) setting the display update clock frequency and 2) setting up a divider for that clock.
0xDB and 0xD9 sets up a parameter that is display dependent. That being said I tried a bunch of different values and they all look the same to me.
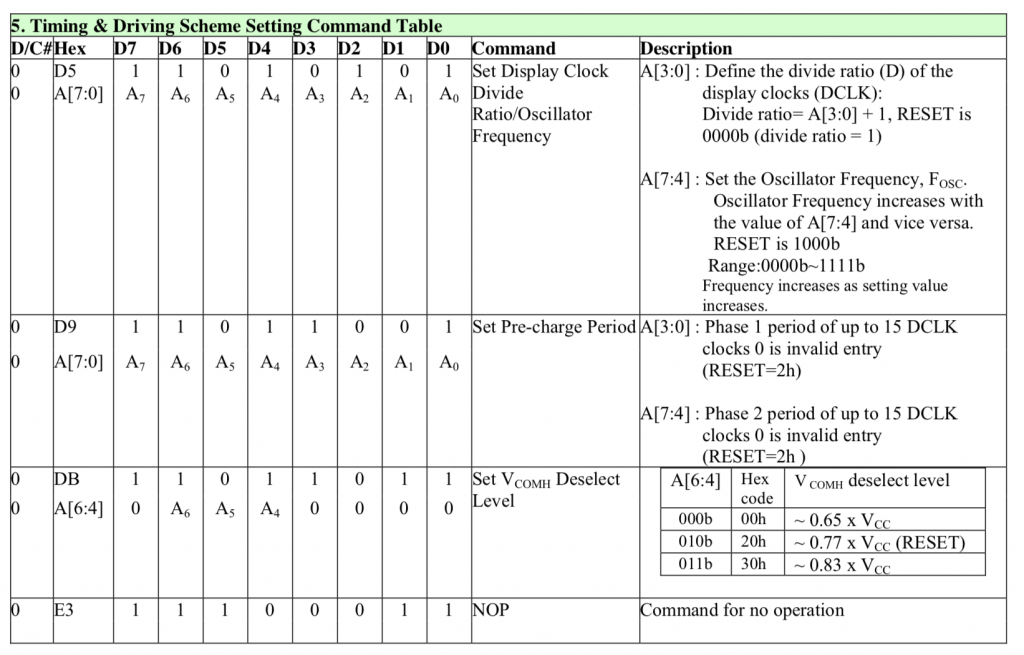
////////////////////////////////////////////////////////////////////////
// Timing and Driving Scheme Settings
////////////////////////////////////////////////////////////////////////
#define OLED_SETDISPLAYCLOCKDIV 0xD5
#define OLED_SETPRECHARGE 0xD9
#define OLED_SETVCOMDESELECT 0xDB
#define OLED_NOP 0xE3
These displays require a high voltage to program the liquid crystal in the display. That voltage can either be supplied by an external pin or by an internal charge pump. All the displays that I have seen use an internal charge pump.
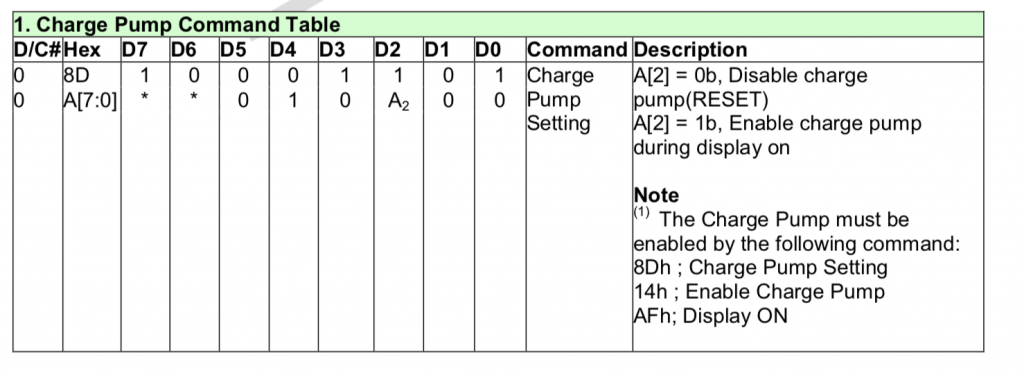
////////////////////////////////////////////////////////////////////////
// Charge Pump Regulator
////////////////////////////////////////////////////////////////////////
#define OLED_CHARGEPUMP 0x8D
#define OLED_CHARGEPUMP_ON 0x14
#define OLED_CHARGEPUMP_OFF 0x10
The SSD1306 Graphics Data RAM
In order to actually get data to display on the screen you need to write 1’s and 0’s into the Graphics Data RAM that represents your image. The memory is actually organized into 8 pages that are each 128 bits wide and 8 bits tall. This means that if you write 0b10101010 to location (0,0) you will get the first 8 pixels in a column on the screen to be on,off,on,off,on,off,on,off. Notice that I said vertical column and not row. Here is a picture from the data sheet. That shows the pages:

And then they show you in the data sheet that the pixels go down from the first row of the page.

In order to make the writing process easier and lower bandwidth the SSD1306 has three automatic addressing modes.
- Horizontal – Set the page address start, end and the column start and end… bytes write 8 vertical pixels on the page. Each byte write advances the column until it wraps to the next page and resets the column to the “start”
- Vertical – Set the page address start, end and the column start and end… bytes write 8 vertical pixels on the page. Each byte write advances the page until it wraps vertically where it increments the column and resets the page back to the start page.
- Page – Set the page address and column start/end. Each byte writes vertically. Wraps back onto the same page when it hits the end column.
In Horizontal and Vertical mode you
- Set the range of columns that you want to write (using 0x22)
- Set the range of pages you want to write (using 0x21)
- Write bytes
In the page mode you
- Set the page (remember you can only write one page at a time in page mode) using 0xB0-0xB7
- Set the start column using 0x0? and 0x1?
Here is a picture from the data sheet of horizontal address mode:

In this bit of example code I am saying to iterate through the pages 0->7… in other words all of the pages. And to start in column 0. This example will make 12 columns of pixels each 8 high starting a (0,0) on the screen…
char horizontalExample[]= {
0xAE,
0x20, /// address mode
0x00, // Horizontal
0xA4,
0xAF,
0x22, //Set page address range
0,
7,
0x21, // column start and end address
0,
127,
};
I2C_WriteCmdStream(horizontalExample, sizeof(horizontalExample));
// Write twelve bytes onto screen with 0b10101010
for(int i=0;i<12;i++)
I2C_WriteData(0xAA);
Here is a picture of what it does.

Here is a picture from the data sheet of vertical address mode:
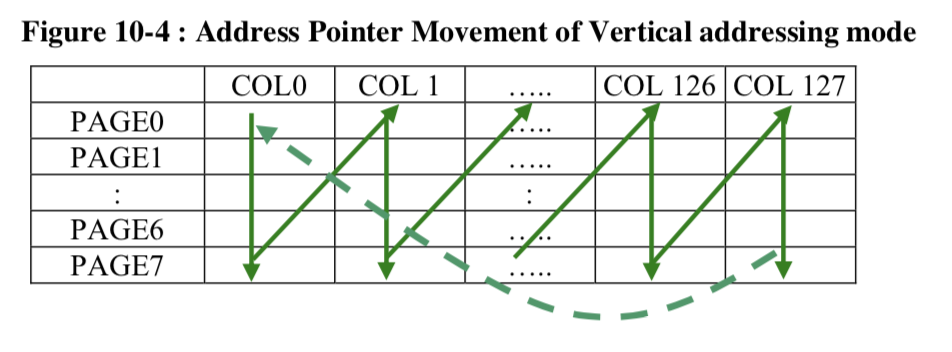
This example code sets the page range to 0–>7 (the whole screen) and the column range 0–>127 (the whole screen). Then writes 12 bytes. You can see it wrap at the bottom and move back to page 0 column 1.
char verticalExample[]= {
0xAE,
0x20, /// address mode
0x01, // vertical
0xA4,
0xAF,
0x22, //Set page address range
0,
7,
0x21, // column start and end address
0,
127,
};
I2C_WriteCmdStream(verticalExample, sizeof(verticalExample));
// Write twelve bytes onto screen with 0b10101010
for(int i=0;i<12;i++)
I2C_WriteData(0xAA);

In page mode you just set the page and the start and end column. 0xB0 means page 0, 0xB1 means page 1… 0xB7 means page 7.
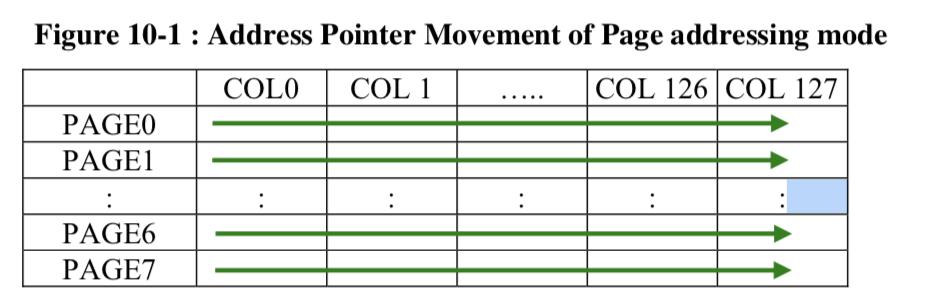
You can see that I started from column 0x78 (meaning column 120) and that it wraps back to column 0 on the SAME page.
char pageExample[]= {
0xAE,
0x20, // address mode
0x02, // Page mode
0xA4, // Resume from ram
0xAF, // Screen on
0xB0, // Start from page 0
// Start from column 0x78 aka 120
0x08, // Column lower nibble address
0x17 // Column upper nibble address
};
I2C_WriteCmdStream(pageExample, sizeof(pageExample));
// Write twelve bytes onto screen with 0b10101010
for(int i=0;i<12;i++)
I2C_WriteData(0xAA);
Here is what it looks like.

Reading from the Frame Buffer
Now that you know how to write to the Frame Buffer, the next question is how do you read? For instance if you want to turn on 1 pixel (of a byte) but leave the others alone can you do this? The answer is NO. In serial mode the device only writes. In all of the Graphics libraries that I have seen they handle this by having a Frame Buffer in the MCU as well. Duplicated resources… oh well.
My Initialization Sequence
I have a function that writes an array of bytes to the command registers. So for me to initialize the screen I just need to set up that array. Here is my best known setup.
const char initializeCmds[]={
//////// Fundamental Commands
OLED_DISPLAYOFF, // 0xAE Screen Off
OLED_SETCONTRAST, // 0x81 Set contrast control
0x7F, // 0-FF ... default half way
OLED_DISPLAYNORMAL, // 0xA6, //Set normal display
//////// Scrolling Commands
OLED_DEACTIVATE_SCROLL, // Deactive scroll
//////// Addressing Commands
OLED_SETMEMORYMODE, // 0x20, //Set memory address mode
OLED_SETMEMORYMODE_PAGE, // Page
//////// Hardware Configuration Commands
OLED_SEGREMAPINV, // 0xA1, //Set segment re-map
OLED_SETMULTIPLEX, // 0xA8 Set multiplex ratio
0x3F, // Vertical Size - 1
OLED_COMSCANDEC, // 0xC0 Set COM output scan direction
OLED_SETDISPLAYOFFSET, // 0xD3 Set Display Offset
0x00, //
OLED_SETCOMPINS, // 0xDA Set COM pins hardware configuration
0x12, // Alternate com config & disable com left/right
//////// Timing and Driving Settings
OLED_SETDISPLAYCLOCKDIV, // 0xD5 Set display oscillator frequency 0-0xF /clock divide ratio 0-0xF
0x80, // Default value
OLED_SETPRECHARGE, // 0xD9 Set pre-changed period
0x22, // Default 0x22
OLED_SETVCOMDESELECT, // 0xDB, //Set VCOMH Deselected level
0x20, // Default
//////// Charge pump regulator
OLED_CHARGEPUMP, // 0x8D Set charge pump
OLED_CHARGEPUMP_ON, // 0x14 VCC generated by internal DC/DC circuit
// Turn the screen back on...
OLED_DISPLAYALLONRESUME, // 0xA4, //Set entire display on/off
OLED_DISPLAYON, // 0xAF //Set display on
};
Some Other Initialization Sequences
If you look around you will find many different SSD1306 libraries. You can run this search on github.
Here is one example from https://github.com/vadzimyatskevich/SSD1306/blob/master/src/ssd1306.c This is pretty much the same as mine except that the author put them in some other order than the data sheet. I am not a huge fan of “ssd1306Command( SSD1306_SEGREMAP | 0x1)” but it does work.
void ssd1306Init(uint8_t vccstate)
{
_font = (FONT_INFO*)&ubuntuMono_24ptFontInfo;
// Initialisation sequence
ssd1306TurnOff();
// 1. set mux ratio
ssd1306Command( SSD1306_SETMULTIPLEX );
ssd1306Command( 0x3F );
// 2. set display offset
ssd1306Command( SSD1306_SETDISPLAYOFFSET );
ssd1306Command( 0x0 );
// 3. set display start line
ssd1306Command( SSD1306_SETSTARTLINE | 0x0 );
ssd1306Command( SSD1306_MEMORYMODE); // 0x20
ssd1306Command( 0x00); // 0x0 act like ks0108
// 4. set Segment re-map A0h/A1h
ssd1306Command( SSD1306_SEGREMAP | 0x1);
// 5. Set COM Output Scan Direction C0h/C8h
ssd1306Command( SSD1306_COMSCANDEC);
// 6. Set COM Pins hardware configuration DAh, 12
ssd1306Command( SSD1306_SETCOMPINS);
ssd1306Command( 0x12);
// 7. Set Contrast Control 81h, 7Fh
ssd1306Command( SSD1306_SETCONTRAST );
if (vccstate == SSD1306_EXTERNALVCC) {
ssd1306Command( 0x9F );
} else {
ssd1306Command( 0xff );
}
// 8. Disable Entire Display On A4h
ssd1306Command( SSD1306_DISPLAYALLON_RESUME);
// 9. Set Normal Display A6h
ssd1306Command( SSD1306_NORMALDISPLAY);
// 10. Set Osc Frequency D5h, 80h
ssd1306Command( SSD1306_SETDISPLAYCLOCKDIV);
ssd1306Command( 0x80);
// 11. Enable charge pump regulator 8Dh, 14h
ssd1306Command( SSD1306_CHARGEPUMP );
if (vccstate == SSD1306_EXTERNALVCC) {
ssd1306Command( 0x10);
} else {
ssd1306Command( 0x14);
}
// 12. Display On AFh
ssd1306TurnOn();
}
Here is another example from git@github.com:lexus2k/ssd1306.git
https://github.com/lexus2k/ssd1306/blob/master/src/lcd/oled_ssd1306.c
Honestly if I had found this originally I would not have gone to all the trouble.
static const uint8_t PROGMEM s_oled128x64_initData[] =
{
#ifdef SDL_EMULATION
SDL_LCD_SSD1306,
0x00,
#endif
SSD1306_DISPLAYOFF, // display off
SSD1306_MEMORYMODE, HORIZONTAL_ADDRESSING_MODE, // Page Addressing mode
SSD1306_COMSCANDEC, // Scan from 127 to 0 (Reverse scan)
SSD1306_SETSTARTLINE | 0x00, // First line to start scanning from
SSD1306_SETCONTRAST, 0x7F, // contast value to 0x7F according to datasheet
SSD1306_SEGREMAP | 0x01, // Use reverse mapping. 0x00 - is normal mapping
SSD1306_NORMALDISPLAY,
SSD1306_SETMULTIPLEX, 63, // Reset to default MUX. See datasheet
SSD1306_SETDISPLAYOFFSET, 0x00, // no offset
SSD1306_SETDISPLAYCLOCKDIV, 0x80,// set to default ratio/osc frequency
SSD1306_SETPRECHARGE, 0x22, // switch precharge to 0x22 // 0xF1
SSD1306_SETCOMPINS, 0x12, // set divide ratio
SSD1306_SETVCOMDETECT, 0x20, // vcom deselect to 0x20 // 0x40
SSD1306_CHARGEPUMP, 0x14, // Enable charge pump
SSD1306_DISPLAYALLON_RESUME,
SSD1306_DISPLAYON,
};
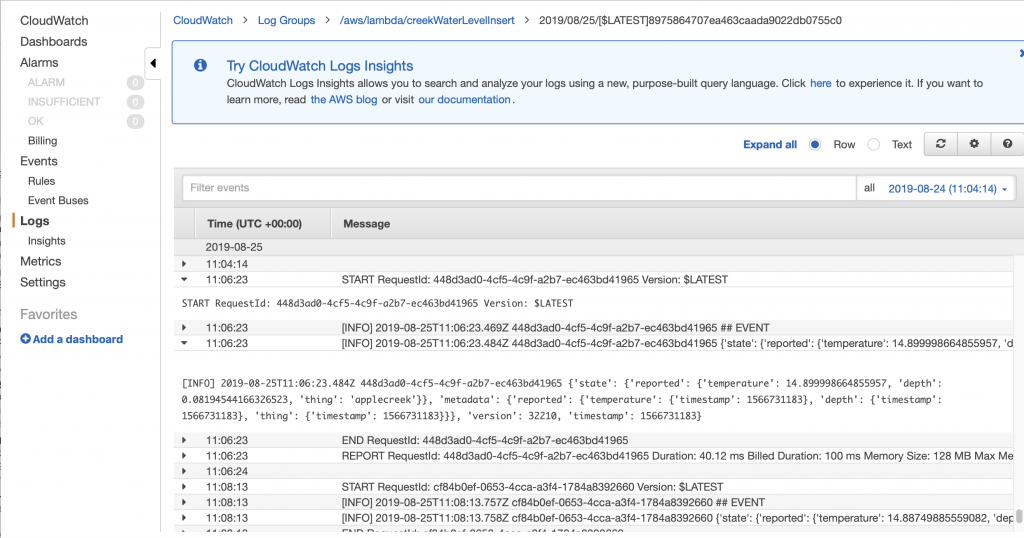
Debug: Test the Hardware
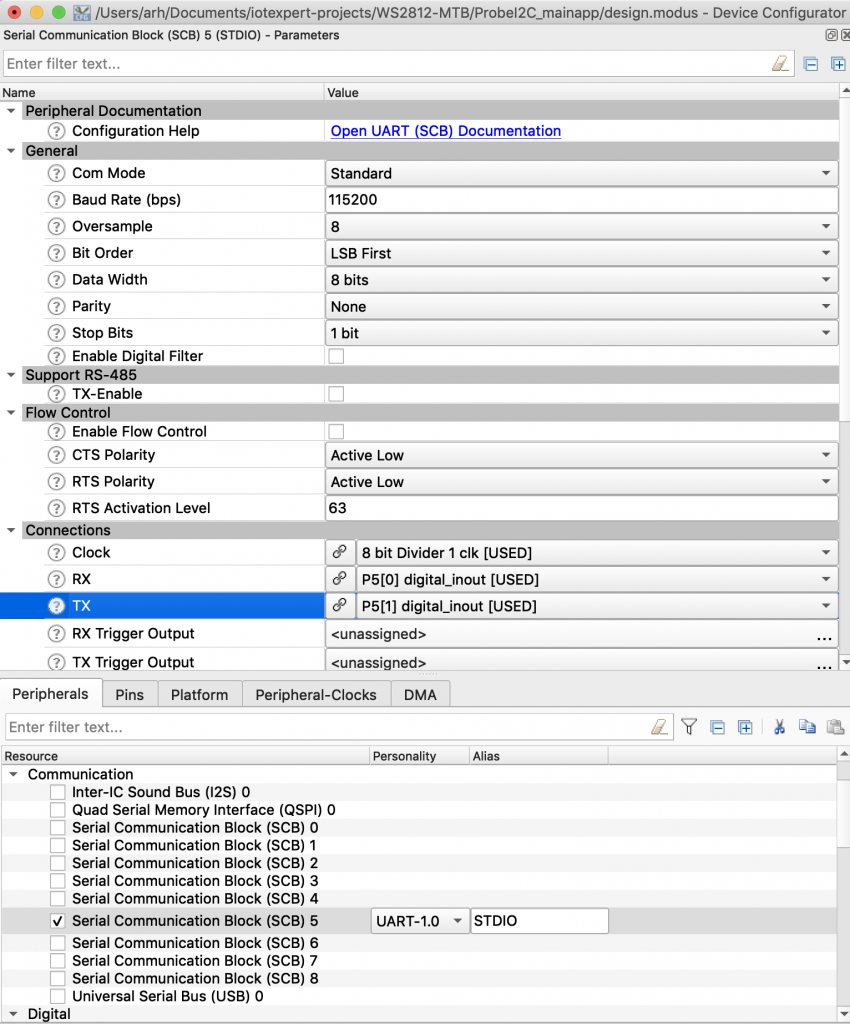
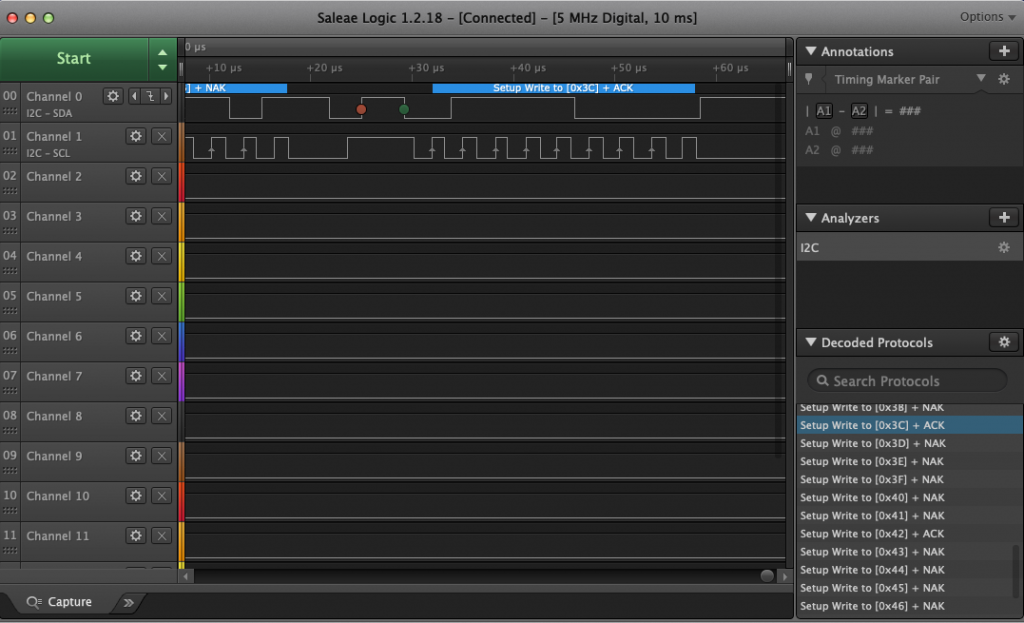
If a your screen is not working, the first thing to do is use a multimeter and make sure that VCC=SCL=SDA=3.3V. (in the picture below my camera caught the screen refresh partially through… It looks fine at normal speed). I have the red probe attached to the SCL.

I would then run the bridge control panel and make sure that the device is responding. You can do this by pressing “List”. In the picture below you can see that there are two devices attached to the bus, my screen is set to 0x78/0x3C.
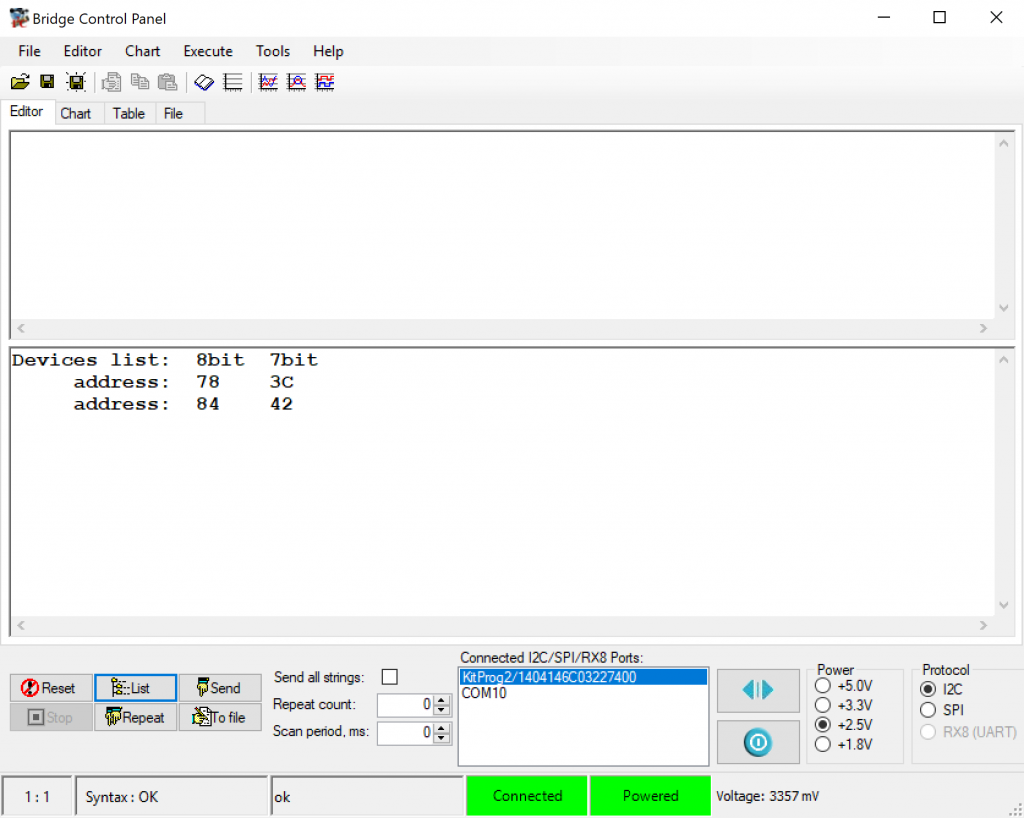
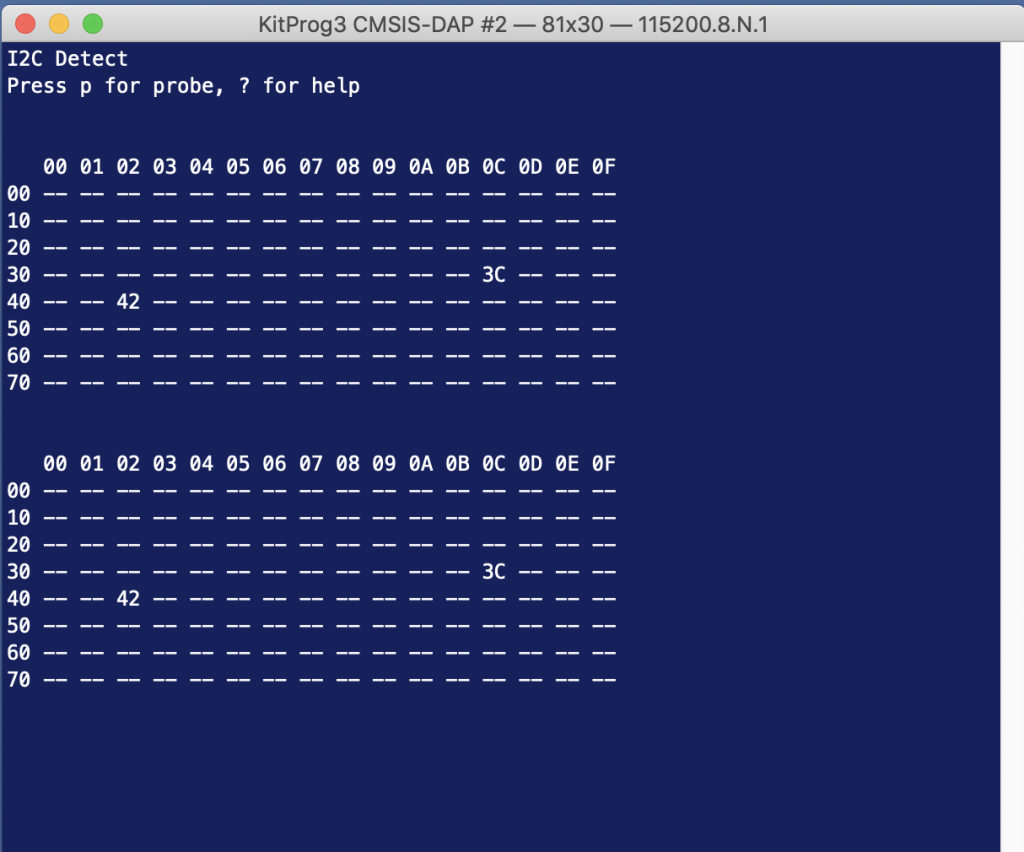
If you don’t have the bridge control panel then you can implement I2Cdetect using your development kit. Read about it here.
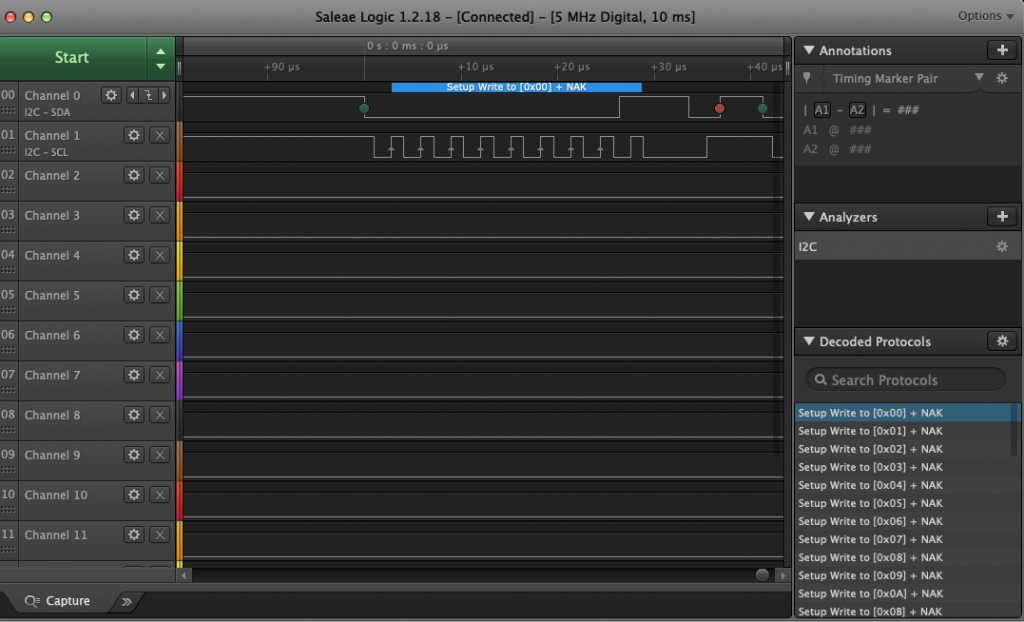
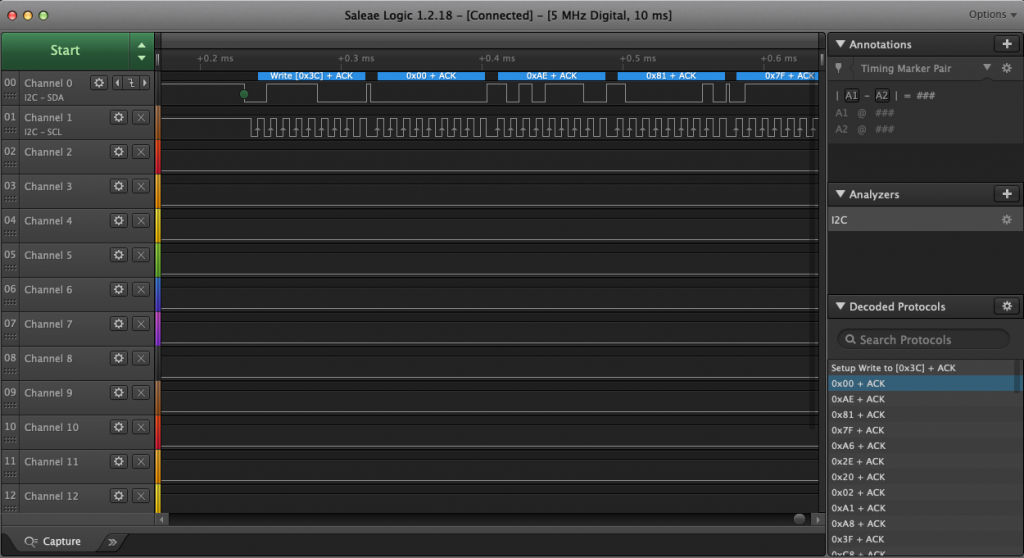
The next thing to do is attach a logic analyzer and make sure that the startup commands are coming out of your MCU correctly. Notice that the 00, 0xAE, 0x81… are exactly the configuration sequence that I wrote in the driver code above.
Debug: Test the Firmware
If your screen is still not working here are some problems and what to do about them.
- Speckled Screen
- Solid Screen
- Screen Flipped in the Y direction
- Screen Flipped in the X Direction
- Screen Flipped in both Directions
- Screen is Inverted
- Image is Partially off the Screen
- Image is Wrapped on the Screen
- Black Screen
- Screen Has Gone Crazy
Speckled Screen
If you have the speckled screen this means that your screen is displaying an uninitialized frame buffer which the SSD people call the GDDRAM. These are basically the random 0 and 1s that are the startup values in the SSD1306. If this is happening then your graphic data is probably not being transferred between your MCU and the SSD1306. This almost certainly means you have a problem in your porting layer.

Speckled Screen
If your screen is solid white that probably means you turned the screen back on without resuming from the graphics ram. You did this:
OLED_DISPLAYALLONIGNORE, // 0xA5, //Set entire display on/off
instead of this:
OLED_DISPLAYALLONRESUME, // 0xA4, //Set entire display on/off

Screen Flipped in the Y direction
The commands C0/C8 set the direction in which the com lines are scanned. Either from top to bottom or bottom to top. Change C0–>C8 to the other way.
#define OLED_COMSCANINC 0xC0
#define OLED_COMSCANDEC 0xC8

Screen Flipped in the X Direction
In the X-Direction the A0/A1 set the configuration of scanning. Try using A0–>A8 or the other way.
// X Direction Scanning
#define OLED_SEGREMAPNORMAL 0xA0
#define OLED_SEGREMAPINV 0xA1

Screen Flipped in both Directions
If it is flipped in both X and Y direction then flip both of the direction registers.
// Y Direction
#define OLED_SEGREMAPNORMAL 0xA0
#define OLED_SEGREMAPINV 0xA1
// X Direction
#define OLED_COMSCANINC 0xC0
#define OLED_COMSCANDEC 0xC8

Screen is Inverted
If your screen is inverted then try A8–>A6
#define OLED_DISPLAYNORMAL 0xA6
#define OLED_DISPLAYINVERT 0xA7

Image is Partially off the Screen
If your image is off the screen the you probably have the wrong value for MULTIPLEX.
#define OLED_SETMULTIPLEX 0xA8
The parameter is supposed to be the number of lines on the screen -1. In my case the screen is 128×64 so my valued should be 63 aka 0x3F
OLED_SETMULTIPLEX, // 0xA8 Set multiplex ratio
0x3F, // Vertical Size - 1

Image is Wrapped on the Screen
// Double byte CMD image wrap ...probably should be 0
#define OLED_SETDISPLAYOFFSET 0xD3
The offset value allows the board designer to hook up the rows in a crazy fashion. My screen has the top row to the top row number.
OLED_SETDISPLAYOFFSET, // 0xD3 Set Display Offset
0x00, //
 \
\
Black Screen
If you screen is totally dead…

Then the charge pump may be off
//////// Charge pump regulator
OLED_CHARGEPUMP, // 0x8D Set charge pump
0x14, // VCC generated by internal DC/DC circuit
or maybe the screen is off… try turning it on.
OLED_DISPLAYON, // 0xAF //Set display on
or maybe you haven’t displayed anything. The screen is off trying sending a screen invert
#define OLED_DISPLAYINVERT 0xA7
The Screen Has Gone Crazy
The register 0xDA SetComPins register will make some crazy results of it isn’t set correctly. For my 0.96″ inch screen it needs to be set to 0x12
// Double Byte Hardware com pins configuration
#define OLED_SETCOMPINS 0xDA
// legal values 0x02, 0x12, 0x022, 0x032
This is what happens with 0x02 [If you see the note below from Ivan, 0x02 is apparently for 128×32 and this screen is 128×64=0x12]
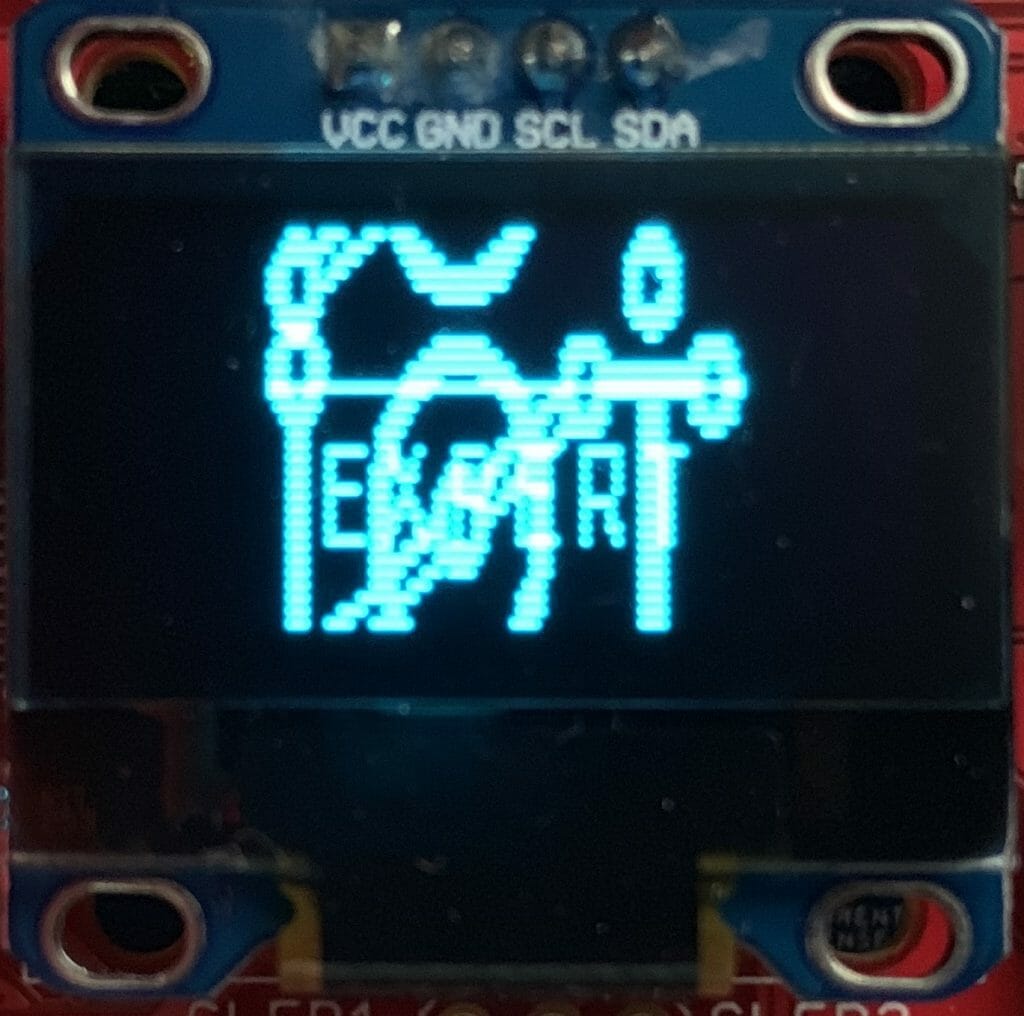
And 0x22

Finally 0x32

This was absolutely the craziest rabbit hole that I have ventured down. Nicholas has talked to me 10 times about doing this and he thinks I’m crazy. Oh well.