Summary
Instructions for installing InfluxDB2 in a docker container and writing a Python program to insert data.
Story
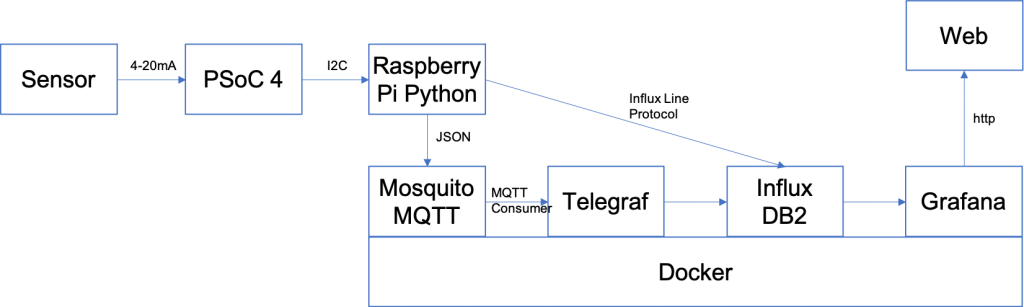
I don’t really have a long complicated story about how I got here. I just wanted to replace my Java, MySQL, Tomcat setup with something newer. I wanted to do it without writing a bunch of code. It seemed like Docker + Influx + Telegraph + Grafana was a good answer. In this article I install Influx DB on my new server using Docker. Then I hookup my Creek data via a Python script.
Docker & InfluxDB
I have become a huge believer in using Docker, I think it is remarkable what they did. I also think that using docker-compose is the correct way to launch new docker containers so that you don’t loose the secret sauce on the command line when doing a “docker run”. Let’s get this whole thing going by creating a new docker-compose.yaml file with the description of our new docker container. It is pretty simple:
- Specify the influxdb image
- Map port 8086 on the client and on the container
- Specify the initial conditions for the Influxdb – these are nicely documented in the installation instructions here.
- Create a volume
version: "3.3" # optional since v1.27.0
services:
influxdb:
image: influxdb
ports:
- "8086:8086"
environment:
- DOCKER_INFLUXDB_INIT_MODE=setup
- DOCKER_INFLUXDB_INIT_USERNAME=root
- DOCKER_INFLUXDB_INIT_PASSWORD=password
- DOCKER_INFLUXDB_INIT_ORG=creekdata
- DOCKER_INFLUXDB_INIT_BUCKET=creekdata
volumes:
- influxdb2:/var/lib/influxdb2
volumes:
influxdb2:
Once you have that file you can run “docker-compose up”… and wait … until everything gets pulled from the docker hub.
arh@spiff:~/influx-telegraf-grafana$ docker-compose up
Creating network "influx-telegraf-grafana_default" with the default driver
Creating volume "influx-telegraf-grafana_influxdb2" with default driver
Pulling influxdb (influxdb:)...
latest: Pulling from library/influxdb
d960726af2be: Pull complete
e8d62473a22d: Pull complete
8962bc0fad55: Pull complete
3b26e21cfb07: Pull complete
f77b907603e3: Pull complete
2b137bdfa0c5: Pull complete
7e6fa243fc79: Pull complete
3e0cae572c4f: Pull complete
9a27f9435a76: Pull complete
Digest: sha256:090ba796c2e5c559b9acede14fc7c1394d633fb730046dd2f2ebf400acc22fc0
Status: Downloaded newer image for influxdb:latest
Creating influx-telegraf-grafana_influxdb_1 ... done
Attaching to influx-telegraf-grafana_influxdb_1
influxdb_1 | 2021-05-19T12:37:14.866162317Z info booting influxd server in the background {"system": "docker"}
influxdb_1 | 2021-05-19T12:37:16.867909370Z info pinging influxd... {"system": "docker"}
influxdb_1 | 2021-05-19T12:37:18.879390124Z info pinging influxd... {"system": "docker"}
influxdb_1 | 2021-05-19T12:37:20.891280023Z info pinging influxd... {"system": "docker"}
influxdb_1 | ts=2021-05-19T12:37:21.065674Z lvl=info msg="Welcome to InfluxDB" log_id=0UD9wCAG000 version=2.0.6 commit=4db98b4c9a build_date=2021-04-29T16:48:12Z
influxdb_1 | ts=2021-05-19T12:37:21.068517Z lvl=info msg="Resources opened" log_id=0UD9wCAG000 service=bolt path=/var/lib/influxdb2/influxd.bolt
influxdb_1 | ts=2021-05-19T12:37:21.069293Z lvl=info msg="Bringing up metadata migrations" log_id=0UD9wCAG000 service=migrations migration_count=15
influxdb_1 | ts=2021-05-19T12:37:21.132269Z lvl=info msg="Using data dir" log_id=0UD9wCAG000 service=storage-engine service=store path=/var/lib/influxdb2/engine/data
influxdb_1 | ts=2021-05-19T12:37:21.132313Z lvl=info msg="Compaction settings" log_id=0UD9wCAG000 service=storage-engine service=store max_concurrent_compactions=3 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
influxdb_1 | ts=2021-05-19T12:37:21.132325Z lvl=info msg="Open store (start)" log_id=0UD9wCAG000 service=storage-engine service=store op_name=tsdb_open op_event=start
influxdb_1 | ts=2021-05-19T12:37:21.132383Z lvl=info msg="Open store (end)" log_id=0UD9wCAG000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.059ms
influxdb_1 | ts=2021-05-19T12:37:21.132407Z lvl=info msg="Starting retention policy enforcement service" log_id=0UD9wCAG000 service=retention check_interval=30m
influxdb_1 | ts=2021-05-19T12:37:21.132428Z lvl=info msg="Starting precreation service" log_id=0UD9wCAG000 service=shard-precreation check_interval=10m advance_period=30m
influxdb_1 | ts=2021-05-19T12:37:21.132446Z lvl=info msg="Starting query controller" log_id=0UD9wCAG000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
influxdb_1 | ts=2021-05-19T12:37:21.133391Z lvl=info msg="Configuring InfluxQL statement executor (zeros indicate unlimited)." log_id=0UD9wCAG000 max_select_point=0 max_select_series=0 max_select_buckets=0
influxdb_1 | ts=2021-05-19T12:37:21.434078Z lvl=info msg=Starting log_id=0UD9wCAG000 service=telemetry interval=8h
influxdb_1 | ts=2021-05-19T12:37:21.434165Z lvl=info msg=Listening log_id=0UD9wCAG000 service=tcp-listener transport=http addr=:9999 port=9999
influxdb_1 | 2021-05-19T12:37:22.905008706Z info pinging influxd... {"system": "docker"}
influxdb_1 | 2021-05-19T12:37:22.920976742Z info got response from influxd, proceeding {"system": "docker"}
influxdb_1 | Config default has been stored in /etc/influxdb2/influx-configs.
influxdb_1 | User Organization Bucket
influxdb_1 | root creekdata creekdata
influxdb_1 | 2021-05-19T12:37:23.043336133Z info Executing user-provided scripts {"system": "docker", "script_dir": "/docker-entrypoint-initdb.d"}
influxdb_1 | 2021-05-19T12:37:23.044663106Z info initialization complete, shutting down background influxd {"system": "docker"}
influxdb_1 | ts=2021-05-19T12:37:23.044900Z lvl=info msg="Terminating precreation service" log_id=0UD9wCAG000 service=shard-precreation
influxdb_1 | ts=2021-05-19T12:37:23.044906Z lvl=info msg=Stopping log_id=0UD9wCAG000 service=telemetry interval=8h
influxdb_1 | ts=2021-05-19T12:37:23.044920Z lvl=info msg=Stopping log_id=0UD9wCAG000 service=scraper
influxdb_1 | ts=2021-05-19T12:37:23.044970Z lvl=info msg=Stopping log_id=0UD9wCAG000 service=tcp-listener
influxdb_1 | ts=2021-05-19T12:37:23.545252Z lvl=info msg=Stopping log_id=0UD9wCAG000 service=task
influxdb_1 | ts=2021-05-19T12:37:23.545875Z lvl=info msg=Stopping log_id=0UD9wCAG000 service=nats
influxdb_1 | ts=2021-05-19T12:37:23.546765Z lvl=info msg=Stopping log_id=0UD9wCAG000 service=bolt
influxdb_1 | ts=2021-05-19T12:37:23.546883Z lvl=info msg=Stopping log_id=0UD9wCAG000 service=query
influxdb_1 | ts=2021-05-19T12:37:23.548747Z lvl=info msg=Stopping log_id=0UD9wCAG000 service=storage-engine
influxdb_1 | ts=2021-05-19T12:37:23.548788Z lvl=info msg="Closing retention policy enforcement service" log_id=0UD9wCAG000 service=retention
influxdb_1 | ts=2021-05-19T12:37:29.740107Z lvl=info msg="Welcome to InfluxDB" log_id=0UD9wj2l000 version=2.0.6 commit=4db98b4c9a build_date=2021-04-29T16:48:12Z
influxdb_1 | ts=2021-05-19T12:37:29.751816Z lvl=info msg="Resources opened" log_id=0UD9wj2l000 service=bolt path=/var/lib/influxdb2/influxd.bolt
influxdb_1 | ts=2021-05-19T12:37:29.756974Z lvl=info msg="Checking InfluxDB metadata for prior version." log_id=0UD9wj2l000 bolt_path=/var/lib/influxdb2/influxd.bolt
influxdb_1 | ts=2021-05-19T12:37:29.757053Z lvl=info msg="Using data dir" log_id=0UD9wj2l000 service=storage-engine service=store path=/var/lib/influxdb2/engine/data
influxdb_1 | ts=2021-05-19T12:37:29.757087Z lvl=info msg="Compaction settings" log_id=0UD9wj2l000 service=storage-engine service=store max_concurrent_compactions=3 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
influxdb_1 | ts=2021-05-19T12:37:29.757099Z lvl=info msg="Open store (start)" log_id=0UD9wj2l000 service=storage-engine service=store op_name=tsdb_open op_event=start
influxdb_1 | ts=2021-05-19T12:37:29.757149Z lvl=info msg="Open store (end)" log_id=0UD9wj2l000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.051ms
influxdb_1 | ts=2021-05-19T12:37:29.757182Z lvl=info msg="Starting retention policy enforcement service" log_id=0UD9wj2l000 service=retention check_interval=30m
influxdb_1 | ts=2021-05-19T12:37:29.757187Z lvl=info msg="Starting precreation service" log_id=0UD9wj2l000 service=shard-precreation check_interval=10m advance_period=30m
influxdb_1 | ts=2021-05-19T12:37:29.757205Z lvl=info msg="Starting query controller" log_id=0UD9wj2l000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
influxdb_1 | ts=2021-05-19T12:37:29.758844Z lvl=info msg="Configuring InfluxQL statement executor (zeros indicate unlimited)." log_id=0UD9wj2l000 max_select_point=0 max_select_series=0 max_select_buckets=0
influxdb_1 | ts=2021-05-19T12:37:30.056855Z lvl=info msg=Listening log_id=0UD9wj2l000 service=tcp-listener transport=http addr=:8086 port=8086
influxdb_1 | ts=2021-05-19T12:37:30.056882Z lvl=info msg=Starting log_id=0UD9wj2l000 service=telemetry interval=8h
After everything is rolling you can open up a web browser and go to “http://localhost:8086” and you should see something like this: (I will sort out the http vs https in a later post – because I don’t actually know how to fix it right now.

Once you enter the account and password (that you configured in the docker-compose.yaml” you will see this screen and you are off to the races.
InfluxDB Basics
Before we go too much further lets talk about some of the basics of the Influx Database. An Influx Database also called a “bucket” has the following built in columns:
- _timestamp: The time for the data point stored in epoch nanosecond format (how’s that for some precision)
- _measurement: A text string name for the a group of related datapoints
- _field: A text string key for the datapoint
- _value: The value of the datapoint
In addition you can add “ad-hoc” columns called “tags” which have a “key” and a “value”
| Organization | A group of users and the related buckets, dashboards and tasks | ||
|---|---|---|---|
| Bucket | A database | ||
| Timestamp | The time of the datapoint measured in epoch nanoseconds | ||
| Field | A field includes a field key stored in the _field column and a field value stored in the _value column. | ||
| Field Set | A field set is a collection of field key-value pairs associated with a timestamp. | ||
| Measurement | A measurement acts as a container for tags | fields | and timestamps. Use a measurement name that describes your data. |
| Tag | Key/Value pairs assigned to a datapoint. They are used to index the datapoints (so searches are faster) |
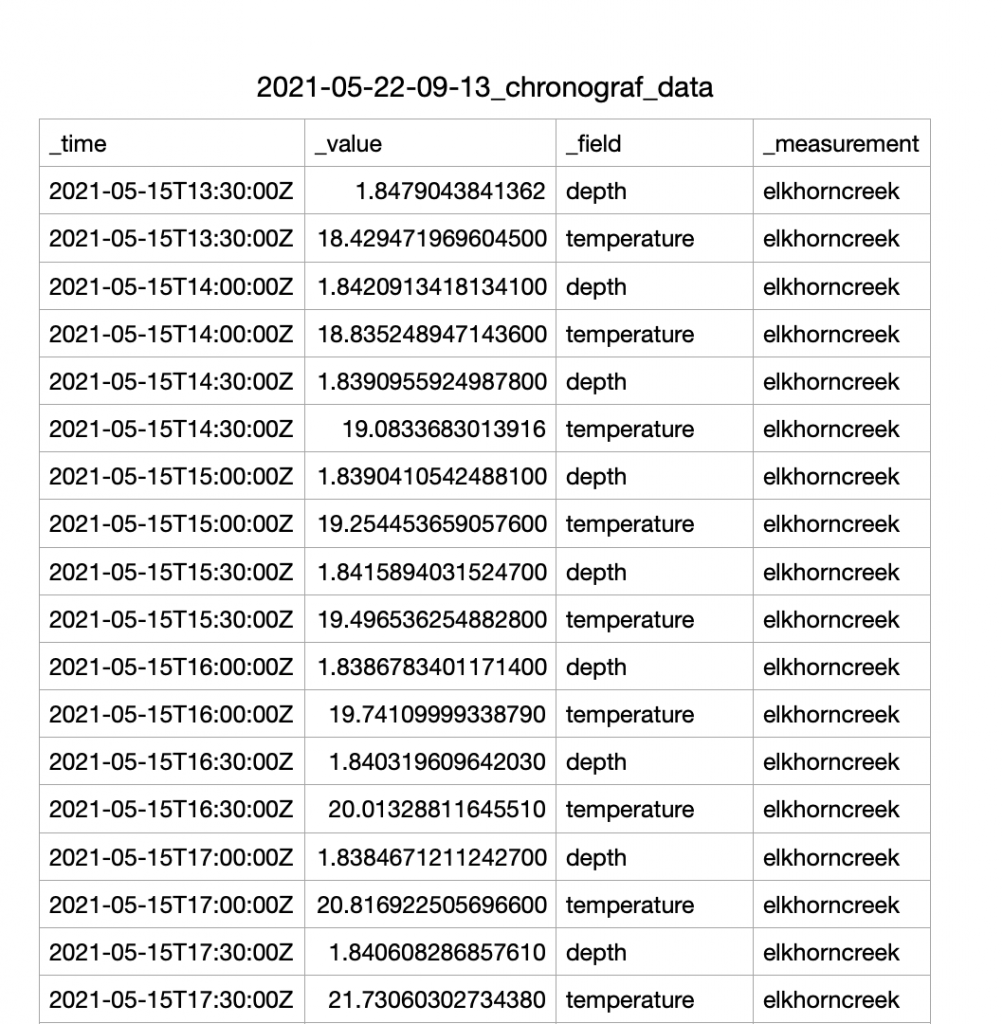
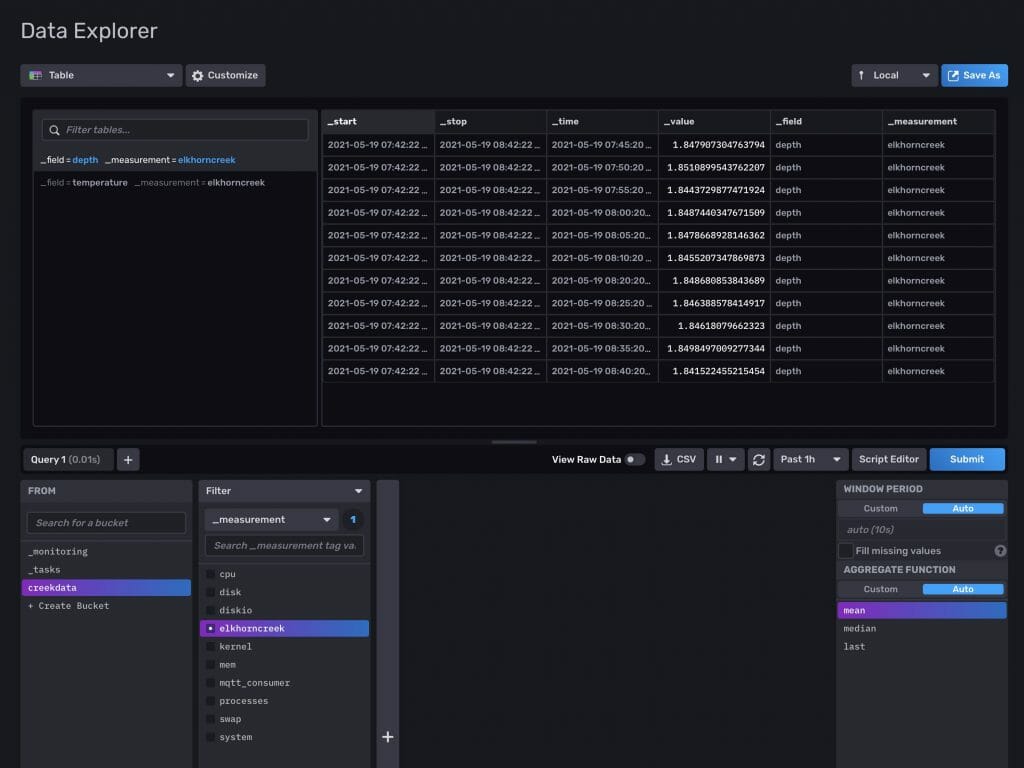
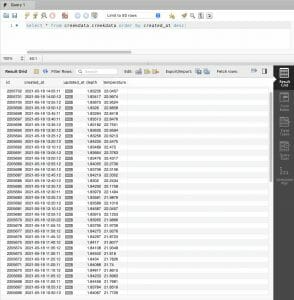
Here is a snapshot of the data in my Creek Influx database. You can see that I have two fields
- depth
- temperature
I am saving all of the datapoints in the “elkhorncreek” _measurement. And there are no tags (but I have ideas for that in the future)
InfluxDB Line Protocol
There are a number of different methods to insert data into the Influx DB. Several of them rely on “Line Protocol“. This is simply a text string formatted like this:

For my purposes a text string like this will insert a new datapoint into the “elkhorncreek” measurement with a depth of 1.85 fee and a temperature of 19c (yes we are a mixed unit household)
- elkhorncreek depth=1.85,temperature=19.0
Python & InfluxDB
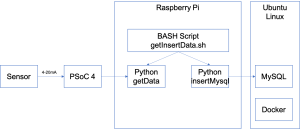
I know that I want to run a Python program on the Raspberry Pi which gets the sensor data via I2C and then writes it into the cloud using the InfluxAPI. It turns out that when you log into you new Influx DB that there is a built in webpage which shows you exactly how to do this. Click on “Data” then “sources” then “Python”

You will see a screen like this which has exactly the Python code you need (almost).
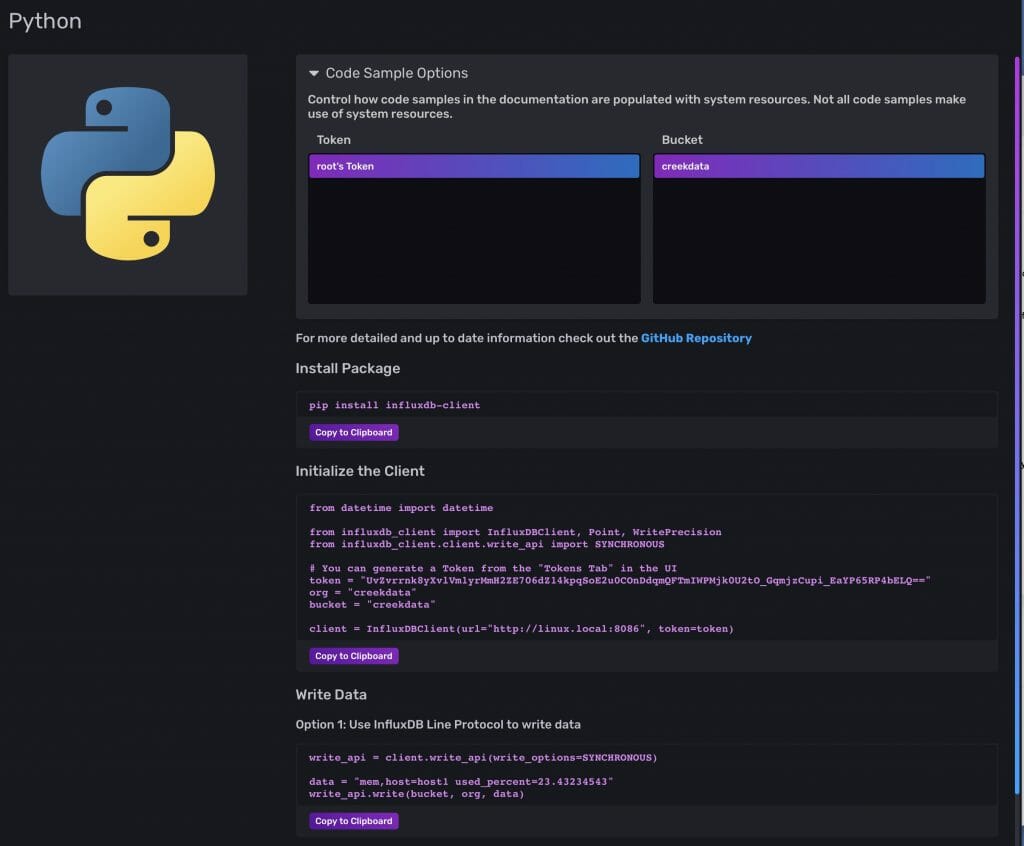
To make this code work on your system you need to install the influxdb-client library by running “pip install influxdb-client”
(venv) pi@iotexpertpi:~/influx-test $ pip install influxdb-client Looking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple Collecting influxdb-client Using cached https://files.pythonhosted.org/packages/6b/0e/5c5a9a2da144fae80b23dd9741175493d8dbeabd17d23e5aff27c92dbfd5/influxdb_client-1.17.0-py3-none-any.whl Collecting urllib3>=1.15.1 (from influxdb-client) Using cached https://files.pythonhosted.org/packages/09/c6/d3e3abe5b4f4f16cf0dfc9240ab7ce10c2baa0e268989a4e3ec19e90c84e/urllib3-1.26.4-py2.py3-none-any.whl Collecting pytz>=2019.1 (from influxdb-client) Using cached https://files.pythonhosted.org/packages/70/94/784178ca5dd892a98f113cdd923372024dc04b8d40abe77ca76b5fb90ca6/pytz-2021.1-py2.py3-none-any.whl Collecting certifi>=14.05.14 (from influxdb-client) Using cached https://files.pythonhosted.org/packages/5e/a0/5f06e1e1d463903cf0c0eebeb751791119ed7a4b3737fdc9a77f1cdfb51f/certifi-2020.12.5-py2.py3-none-any.whl Collecting rx>=3.0.1 (from influxdb-client) Using cached https://files.pythonhosted.org/packages/e2/a9/efeaeca4928a9a56d04d609b5730994d610c82cf4d9dd7aa173e6ef4233e/Rx-3.2.0-py3-none-any.whl Collecting six>=1.10 (from influxdb-client) Using cached https://files.pythonhosted.org/packages/d9/5a/e7c31adbe875f2abbb91bd84cf2dc52d792b5a01506781dbcf25c91daf11/six-1.16.0-py2.py3-none-any.whl Requirement already satisfied: setuptools>=21.0.0 in ./venv/lib/python3.7/site-packages (from influxdb-client) (40.8.0) Collecting python-dateutil>=2.5.3 (from influxdb-client) Using cached https://files.pythonhosted.org/packages/d4/70/d60450c3dd48ef87586924207ae8907090de0b306af2bce5d134d78615cb/python_dateutil-2.8.1-py2.py3-none-any.whl Installing collected packages: urllib3, pytz, certifi, rx, six, python-dateutil, influxdb-client Successfully installed certifi-2020.12.5 influxdb-client-1.17.0 python-dateutil-2.8.1 pytz-2021.1 rx-3.2.0 six-1.16.0 urllib3-1.26.4 (venv) pi@iotexpertpi:~/influx-test $
Now write a little bit of code. If you remember from the previous post I run a cronjob that gets the data from the I2C. It will then run this program to do the insert of the data into the Influxdb. Notice that I get the depth and temperature from the command line. The “token” is an API key which you must include with requests to identify you are having permission to write into the database (more on this later). The “data” variable is just a string formatted in “Influx Line Protocol”
import sys
from datetime import datetime
from influxdb_client import InfluxDBClient, Point, WritePrecision
from influxdb_client.client.write_api import SYNCHRONOUS
if len(sys.argv) != 3:
sys.exit("Wrong number of arguments")
# You can generate a Token from the "Tokens Tab" in the UI
token = "UvZvrrnk8yXvlVm1yrMmH2ZE706dZ14kpqSoE2u0COnDdqmQFTmIWPMjk0U2tO_GqmjzCupi_EaYP65RP4bELQ=="
org = "creekdata"
bucket = "creekdata"
client = InfluxDBClient(url="http://linux.local:8086", token=token)
write_api = client.write_api(write_options=SYNCHRONOUS)
data = f"elkhorncreek depth={sys.argv[1]},temperature={sys.argv[2]}"
write_api.write(bucket, org, data)
#print(data)
Now I update my getInsertData.sh shell script to run the Influx as well as the original MySQL insert.
#!/bin/bash cd ~/influxdb source venv/bin/activate vals=$(python getData.py) #echo $vals python insertMysql.py $vals python insertInflux.py $vals
InfluxDB Data Explorer
After a bit of time (for some inserts to happen) I go to the data explorer in the web interface. You can see that I have a number of readings. This is filtering for “depth”
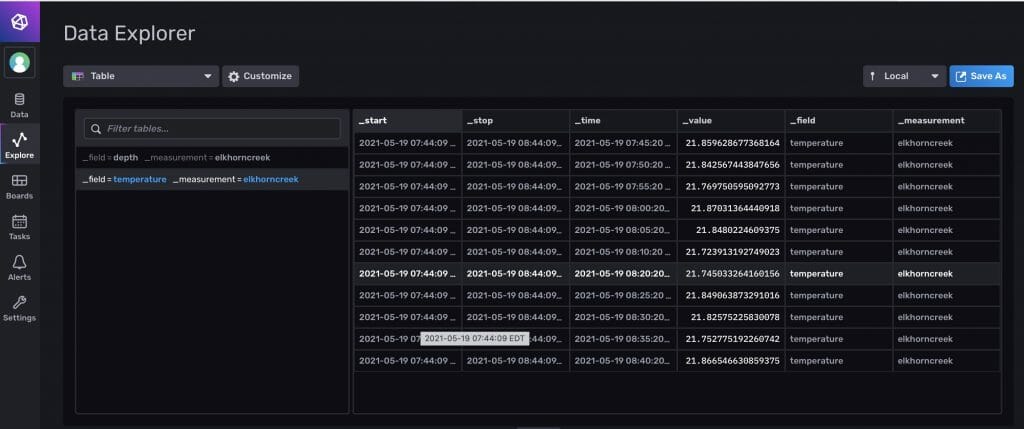
This is filtering for “temperature”
Influx Tokens
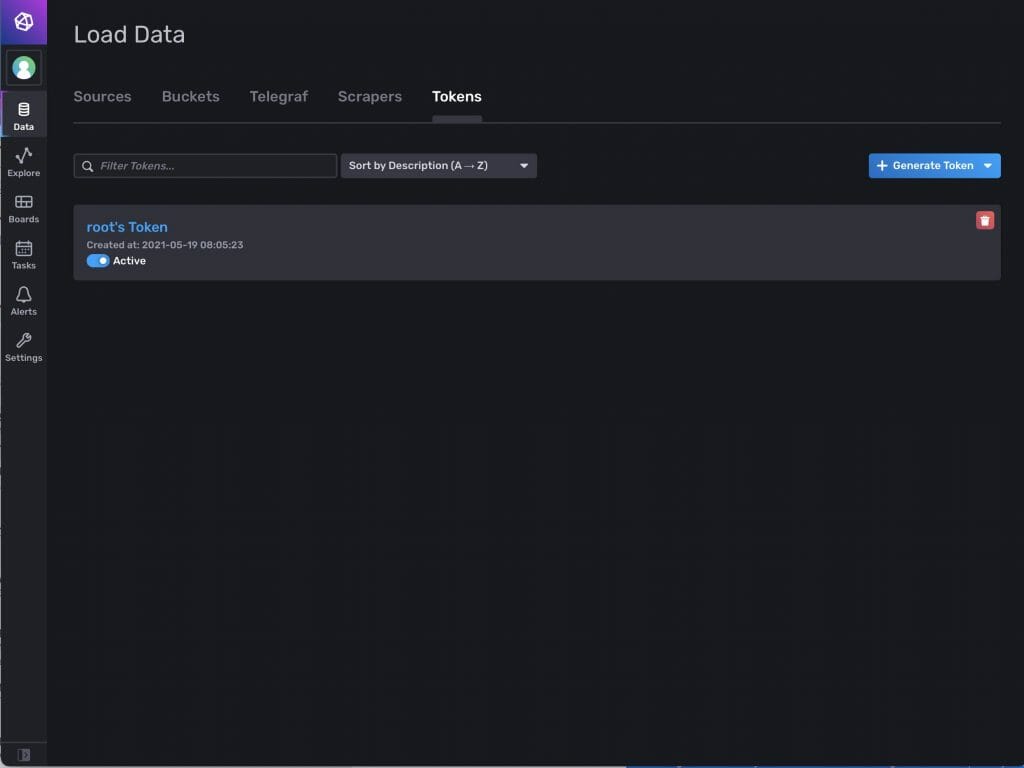
To interact with an instance of the InfluxDB you will need an API key, which they call a token. Press the “data” icon on the left side of the screen. Then click “Tokens”. You will see the currently available tokens, in this case just the original token. You can create more tokens by pressing the blue + generate Token icon.
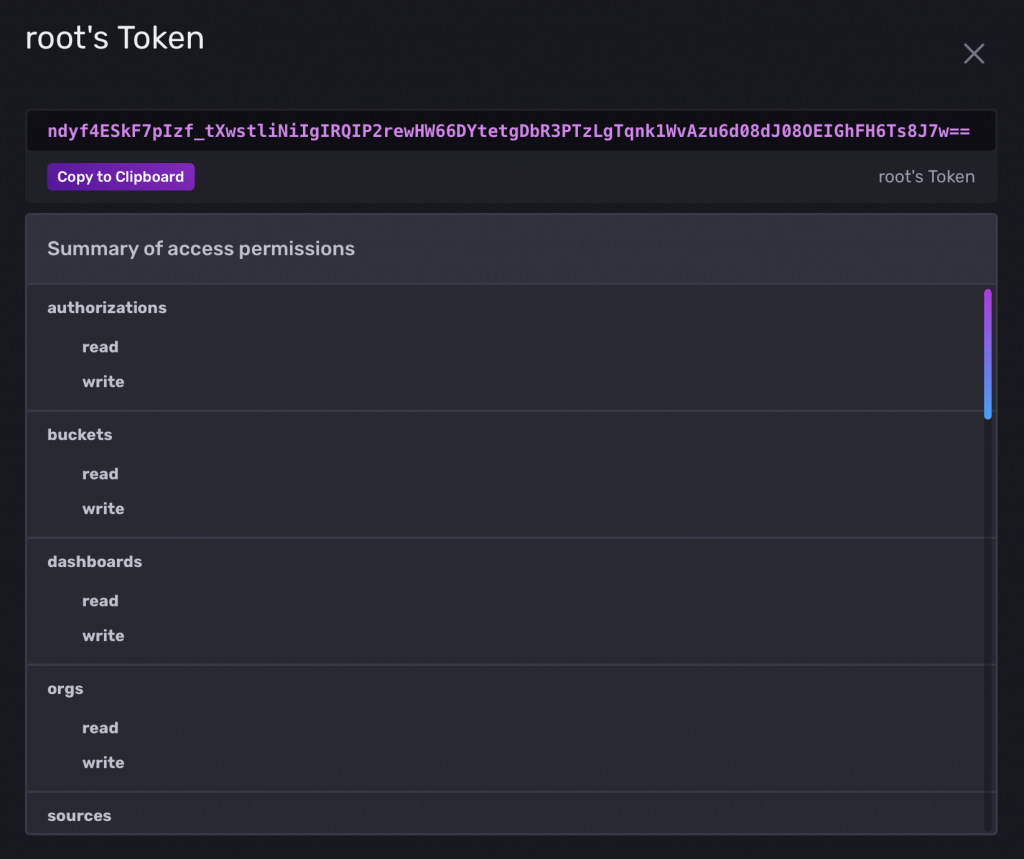
Clock on the token. Then copy it to your clipboard.


2 Comments
i have done same scenario but found influxDB frequently restarted
Upgrade
Sign in
influxdb
influxdb
RUNNING
2021-08-05T04:39:35.715045000Z info booting influxd server in the background {“system”: “docker”}
2021-08-05T04:39:36.718073100Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “0”}
2021-08-05T04:39:37.742799400Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “1”}
2021-08-05T04:39:38.768496800Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “2”}
2021-08-05T04:39:39.792216000Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “3”}
2021-08-05T04:39:40.812213300Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “4”}
2021-08-05T04:39:41.832831300Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “5”}
2021-08-05T04:39:42.856217900Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “6”}
2021-08-05T04:39:43.881881200Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “7”}
2021-08-05T04:39:44.914778600Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “8”}
2021-08-05T04:39:45.946936300Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “9”}
2021-08-05T04:39:46.973083400Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “10”}
2021-08-05T04:39:47.998540000Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “11”}
2021-08-05T04:39:49.025898800Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “12”}
2021-08-05T04:39:50.049666400Z info pinging influxd… {“system”: “docker”, “ping_attempt”: “13”}
2021-08-05T04:39:50.095667500Z info got response from influxd, proceeding {“system”: “docker”, “total_pings”: “14”}
ts=2021-08-05T04:39:43.539572Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9bChl000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:39:43.695382Z lvl=info msg=”Resources opened” log_id=0Vm9bChl000 service=bolt path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:39:43.737120Z lvl=info msg=”Bringing up metadata migrations” log_id=0Vm9bChl000 service=migrations migration_count=15
ts=2021-08-05T04:39:49.147742Z lvl=info msg=”Using data dir” log_id=0Vm9bChl000 service=storage-engine service=store path=/var/lib/influxdb2/engine/data
ts=2021-08-05T04:39:49.147937Z lvl=info msg=”Compaction settings” log_id=0Vm9bChl000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:39:49.147972Z lvl=info msg=”Open store (start)” log_id=0Vm9bChl000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:39:49.148119Z lvl=info msg=”Open store (end)” log_id=0Vm9bChl000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.147ms
ts=2021-08-05T04:39:49.148193Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9bChl000 service=retention check_interval=30m
ts=2021-08-05T04:39:49.148222Z lvl=info msg=”Starting precreation service” log_id=0Vm9bChl000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:39:49.148319Z lvl=info msg=”Starting query controller” log_id=0Vm9bChl000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:39:49.150810Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9bChl000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:39:49.691098Z lvl=info msg=Listening log_id=0Vm9bChl000 service=tcp-listener transport=http addr=:9999 port=9999
ts=2021-08-05T04:39:49.691137Z lvl=info msg=Starting log_id=0Vm9bChl000 service=telemetry interval=8h
Config default has been stored in /etc/influxdb2/influx-configs.
User Organization Bucket
root ST jmeter
ts=2021-08-05T04:39:51.033988Z lvl=info msg=”Terminating precreation service” log_id=0Vm9bChl000 service=shard-precreation
ts=2021-08-05T04:39:51.034049Z lvl=info msg=Stopping log_id=0Vm9bChl000 service=telemetry interval=8h
ts=2021-08-05T04:39:51.034053Z lvl=info msg=Stopping log_id=0Vm9bChl000 service=scraper
ts=2021-08-05T04:39:51.034114Z lvl=info msg=Stopping log_id=0Vm9bChl000 service=tcp-listener
ts=2021-08-05T04:39:51.534645Z lvl=info msg=Stopping log_id=0Vm9bChl000 service=task
ts=2021-08-05T04:39:51.535465Z lvl=info msg=Stopping log_id=0Vm9bChl000 service=nats
ts=2021-08-05T04:39:51.537310Z lvl=info msg=Stopping log_id=0Vm9bChl000 service=bolt
ts=2021-08-05T04:39:51.537676Z lvl=info msg=Stopping log_id=0Vm9bChl000 service=query
ts=2021-08-05T04:39:51.539760Z lvl=info msg=Stopping log_id=0Vm9bChl000 service=storage-engine
ts=2021-08-05T04:39:51.539801Z lvl=info msg=”Closing retention policy enforcement service” log_id=0Vm9bChl000 service=retention
ts=2021-08-05T04:39:59.205179Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9c9u0000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:39:59.250648Z lvl=info msg=”Resources opened” log_id=0Vm9c9u0000 service=bolt path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:39:59.534522Z lvl=info msg=”Checking InfluxDB metadata for prior version.” log_id=0Vm9c9u0000 bolt_path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:39:59.534711Z lvl=info msg=”Using data dir” log_id=0Vm9c9u0000 service=storage-engine service=store path=/var/lib/influxdb2/engine/data
ts=2021-08-05T04:39:59.534744Z lvl=info msg=”Compaction settings” log_id=0Vm9c9u0000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:39:59.534756Z lvl=info msg=”Open store (start)” log_id=0Vm9c9u0000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:39:59.534960Z lvl=info msg=”Open store (end)” log_id=0Vm9c9u0000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.204ms
ts=2021-08-05T04:39:59.535037Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9c9u0000 service=retention check_interval=30m
ts=2021-08-05T04:39:59.535078Z lvl=info msg=”Starting precreation service” log_id=0Vm9c9u0000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:39:59.535215Z lvl=info msg=”Starting query controller” log_id=0Vm9c9u0000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:39:59.537885Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9c9u0000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:40:00.021263Z lvl=info msg=Starting log_id=0Vm9c9u0000 service=telemetry interval=8h
ts=2021-08-05T04:40:00.021406Z lvl=info msg=Listening log_id=0Vm9c9u0000 service=tcp-listener transport=http addr=:8086 port=8086
Waiting InfluxDB to start
ID Name Retention Shard group duration Organization ID
34f45fe6c9fdaaf3 telegraf1 8736h0m0s 168h0m0s f354594d0e9b64e1
ts=2021-08-05T04:40:12.865354Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9c~GG000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:40:13.061701Z lvl=info msg=”Resources opened” log_id=0Vm9c~GG000 service=bolt path=/root/.influxdbv2/influxd.bolt
ts=2021-08-05T04:40:13.102959Z lvl=info msg=”Bringing up metadata migrations” log_id=0Vm9c~GG000 service=migrations migration_count=15
ts=2021-08-05T04:40:17.905521Z lvl=info msg=”Using data dir” log_id=0Vm9c~GG000 service=storage-engine service=store path=/root/.influxdbv2/engine/data
ts=2021-08-05T04:40:17.905950Z lvl=info msg=”Compaction settings” log_id=0Vm9c~GG000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:40:17.906056Z lvl=info msg=”Open store (start)” log_id=0Vm9c~GG000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:40:17.906359Z lvl=info msg=”Open store (end)” log_id=0Vm9c~GG000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.276ms
ts=2021-08-05T04:40:17.906509Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9c~GG000 service=retention check_interval=30m
ts=2021-08-05T04:40:17.906757Z lvl=info msg=”Starting precreation service” log_id=0Vm9c~GG000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:40:17.906878Z lvl=info msg=”Starting query controller” log_id=0Vm9c~GG000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:40:17.910980Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9c~GG000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:40:18.353351Z lvl=info msg=Starting log_id=0Vm9c~GG000 service=telemetry interval=8h
ts=2021-08-05T04:40:18.353352Z lvl=error msg=”Failed to set up TCP listener” log_id=0Vm9c~GG000 service=tcp-listener addr=:8086 error=”listen tcp :8086: bind: address already in use”
ts=2021-08-05T04:40:28.541344Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9dxV0000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:40:28.586877Z lvl=info msg=”Resources opened” log_id=0Vm9dxV0000 service=bolt path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:40:28.896077Z lvl=info msg=”Checking InfluxDB metadata for prior version.” log_id=0Vm9dxV0000 bolt_path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:40:28.896281Z lvl=info msg=”Using data dir” log_id=0Vm9dxV0000 service=storage-engine service=store path=/var/lib/influxdb2/engine/data
ts=2021-08-05T04:40:28.896364Z lvl=info msg=”Compaction settings” log_id=0Vm9dxV0000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:40:28.896380Z lvl=info msg=”Open store (start)” log_id=0Vm9dxV0000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:40:28.896472Z lvl=info msg=”Open store (end)” log_id=0Vm9dxV0000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.093ms
ts=2021-08-05T04:40:28.896587Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9dxV0000 service=retention check_interval=30m
ts=2021-08-05T04:40:28.896627Z lvl=info msg=”Starting precreation service” log_id=0Vm9dxV0000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:40:28.896667Z lvl=info msg=”Starting query controller” log_id=0Vm9dxV0000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:40:28.899069Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9dxV0000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:40:29.325210Z lvl=info msg=Listening log_id=0Vm9dxV0000 service=tcp-listener transport=http addr=:8086 port=8086
ts=2021-08-05T04:40:29.325255Z lvl=info msg=Starting log_id=0Vm9dxV0000 service=telemetry interval=8h
ts=2021-08-05T04:40:40.109836Z lvl=info msg=Unauthorized log_id=0Vm9dxV0000 error=”token required”
Waiting InfluxDB to start
ts=2021-08-05T04:40:50.692619Z lvl=error msg=”Unable to cleanup bucket after create failed” log_id=0Vm9dxV0000 error=”bucket not found”
ts=2021-08-05T04:40:50.692672Z lvl=error msg=”api error encountered” log_id=0Vm9dxV0000 handler=bucket error=”bucket with name telegraf1 already exists”
Error: Failed to create bucket: bucket with name telegraf1 already exists.
See ‘influx bucket create -h’ for help
ts=2021-08-05T04:40:59.677604Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9fr7G000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:40:59.788716Z lvl=info msg=”Resources opened” log_id=0Vm9fr7G000 service=bolt path=/root/.influxdbv2/influxd.bolt
ts=2021-08-05T04:41:00.122140Z lvl=info msg=”Using data dir” log_id=0Vm9fr7G000 service=storage-engine service=store path=/root/.influxdbv2/engine/data
ts=2021-08-05T04:41:00.122241Z lvl=info msg=”Compaction settings” log_id=0Vm9fr7G000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:41:00.122260Z lvl=info msg=”Open store (start)” log_id=0Vm9fr7G000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:41:00.122397Z lvl=info msg=”Open store (end)” log_id=0Vm9fr7G000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.139ms
ts=2021-08-05T04:41:00.122496Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9fr7G000 service=retention check_interval=30m
ts=2021-08-05T04:41:00.122570Z lvl=info msg=”Starting precreation service” log_id=0Vm9fr7G000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:41:00.122631Z lvl=info msg=”Starting query controller” log_id=0Vm9fr7G000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:41:00.124910Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9fr7G000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:41:00.561502Z lvl=error msg=”Failed to set up TCP listener” log_id=0Vm9fr7G000 service=tcp-listener addr=:8086 error=”listen tcp :8086: bind: address already in use”
ts=2021-08-05T04:41:00.561568Z lvl=info msg=Starting log_id=0Vm9fr7G000 service=telemetry interval=8h
ts=2021-08-05T04:41:11.091343Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9gYhW000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:41:11.146036Z lvl=info msg=”Resources opened” log_id=0Vm9gYhW000 service=bolt path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:41:11.471565Z lvl=info msg=”Checking InfluxDB metadata for prior version.” log_id=0Vm9gYhW000 bolt_path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:41:11.471745Z lvl=info msg=”Using data dir” log_id=0Vm9gYhW000 service=storage-engine service=store path=/var/lib/influxdb2/engine/data
ts=2021-08-05T04:41:11.471770Z lvl=info msg=”Compaction settings” log_id=0Vm9gYhW000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:41:11.471800Z lvl=info msg=”Open store (start)” log_id=0Vm9gYhW000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:41:11.471869Z lvl=info msg=”Open store (end)” log_id=0Vm9gYhW000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.070ms
ts=2021-08-05T04:41:11.471959Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9gYhW000 service=retention check_interval=30m
ts=2021-08-05T04:41:11.471981Z lvl=info msg=”Starting precreation service” log_id=0Vm9gYhW000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:41:11.472039Z lvl=info msg=”Starting query controller” log_id=0Vm9gYhW000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:41:11.473513Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9gYhW000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:41:11.943969Z lvl=info msg=Starting log_id=0Vm9gYhW000 service=telemetry interval=8h
ts=2021-08-05T04:41:11.944100Z lvl=info msg=Listening log_id=0Vm9gYhW000 service=tcp-listener transport=http addr=:8086 port=8086
Waiting InfluxDB to start
ts=2021-08-05T04:41:32.458328Z lvl=error msg=”Unable to cleanup bucket after create failed” log_id=0Vm9gYhW000 error=”bucket not found”
ts=2021-08-05T04:41:32.458364Z lvl=error msg=”api error encountered” log_id=0Vm9gYhW000 handler=bucket error=”bucket with name telegraf1 already exists”
Error: Failed to create bucket: bucket with name telegraf1 already exists.
See ‘influx bucket create -h’ for help
ts=2021-08-05T04:41:40.236469Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9iKZ0000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:41:40.282549Z lvl=info msg=”Resources opened” log_id=0Vm9iKZ0000 service=bolt path=/root/.influxdbv2/influxd.bolt
ts=2021-08-05T04:41:40.574808Z lvl=info msg=”Using data dir” log_id=0Vm9iKZ0000 service=storage-engine service=store path=/root/.influxdbv2/engine/data
ts=2021-08-05T04:41:40.574923Z lvl=info msg=”Compaction settings” log_id=0Vm9iKZ0000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:41:40.574942Z lvl=info msg=”Open store (start)” log_id=0Vm9iKZ0000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:41:40.575067Z lvl=info msg=”Open store (end)” log_id=0Vm9iKZ0000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.126ms
ts=2021-08-05T04:41:40.575213Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9iKZ0000 service=retention check_interval=30m
ts=2021-08-05T04:41:40.575276Z lvl=info msg=”Starting precreation service” log_id=0Vm9iKZ0000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:41:40.575434Z lvl=info msg=”Starting query controller” log_id=0Vm9iKZ0000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:41:40.579160Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9iKZ0000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:41:41.005362Z lvl=info msg=Starting log_id=0Vm9iKZ0000 service=telemetry interval=8h
ts=2021-08-05T04:41:41.005415Z lvl=error msg=”Failed to set up TCP listener” log_id=0Vm9iKZ0000 service=tcp-listener addr=:8086 error=”listen tcp :8086: bind: address already in use”
ts=2021-08-05T04:41:51.298641Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9i~lW000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:41:51.355108Z lvl=info msg=”Resources opened” log_id=0Vm9i~lW000 service=bolt path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:41:51.821164Z lvl=info msg=”Checking InfluxDB metadata for prior version.” log_id=0Vm9i~lW000 bolt_path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:41:51.821329Z lvl=info msg=”Using data dir” log_id=0Vm9i~lW000 service=storage-engine service=store path=/var/lib/influxdb2/engine/data
ts=2021-08-05T04:41:51.821357Z lvl=info msg=”Compaction settings” log_id=0Vm9i~lW000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:41:51.821414Z lvl=info msg=”Open store (start)” log_id=0Vm9i~lW000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:41:51.821543Z lvl=info msg=”Open store (end)” log_id=0Vm9i~lW000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.144ms
ts=2021-08-05T04:41:51.821634Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9i~lW000 service=retention check_interval=30m
ts=2021-08-05T04:41:51.821666Z lvl=info msg=”Starting precreation service” log_id=0Vm9i~lW000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:41:51.821777Z lvl=info msg=”Starting query controller” log_id=0Vm9i~lW000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:41:51.824447Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9i~lW000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:41:52.343211Z lvl=info msg=Starting log_id=0Vm9i~lW000 service=telemetry interval=8h
ts=2021-08-05T04:41:52.343231Z lvl=info msg=Listening log_id=0Vm9i~lW000 service=tcp-listener transport=http addr=:8086 port=8086
Waiting InfluxDB to start
ts=2021-08-05T04:42:12.906190Z lvl=error msg=”Unable to cleanup bucket after create failed” log_id=0Vm9i~lW000 error=”bucket not found”
ts=2021-08-05T04:42:12.906252Z lvl=error msg=”api error encountered” log_id=0Vm9i~lW000 handler=bucket error=”bucket with name telegraf1 already exists”
Error: Failed to create bucket: bucket with name telegraf1 already exists.
See ‘influx bucket create -h’ for help
ts=2021-08-05T04:42:20.436092Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9km_l000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:42:20.482838Z lvl=info msg=”Resources opened” log_id=0Vm9km_l000 service=bolt path=/root/.influxdbv2/influxd.bolt
ts=2021-08-05T04:42:20.805054Z lvl=info msg=”Using data dir” log_id=0Vm9km_l000 service=storage-engine service=store path=/root/.influxdbv2/engine/data
ts=2021-08-05T04:42:20.805136Z lvl=info msg=”Compaction settings” log_id=0Vm9km_l000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:42:20.805151Z lvl=info msg=”Open store (start)” log_id=0Vm9km_l000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:42:20.805242Z lvl=info msg=”Open store (end)” log_id=0Vm9km_l000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.091ms
ts=2021-08-05T04:42:20.805351Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9km_l000 service=retention check_interval=30m
ts=2021-08-05T04:42:20.805405Z lvl=info msg=”Starting precreation service” log_id=0Vm9km_l000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:42:20.805477Z lvl=info msg=”Starting query controller” log_id=0Vm9km_l000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:42:20.807849Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9km_l000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:42:21.235692Z lvl=error msg=”Failed to set up TCP listener” log_id=0Vm9km_l000 service=tcp-listener addr=:8086 error=”listen tcp :8086: bind: address already in use”
ts=2021-08-05T04:42:21.235868Z lvl=info msg=Starting log_id=0Vm9km_l000 service=telemetry interval=8h
2021-08-05T04:39:51.029909400Z info Executing user-provided scripts {“system”: “docker”, “script_dir”: “/docker-entrypoint-initdb.d”}
2021-08-05T04:39:51.033032800Z info initialization complete, shutting down background influxd {“system”: “docker”}
+ influx bucket create -n telegraf1 -r 52w -o ST -t randomTokenValue
+ wait 363
Error: listen tcp :8086: bind: address already in use
See ‘influxd -h’ for help
2021-08-05T04:40:20.964484100Z info found existing boltdb file, skipping setup wrapper {“system”: “docker”, “bolt_path”: “/var/lib/influxdb2/influxd.bolt”}
+ influx bucket create -n telegraf1 -r 52w -o ST -t randomTokenValue
+ wait 114
Error: listen tcp :8086: bind: address already in use
See ‘influxd -h’ for help
2021-08-05T04:41:02.745937500Z info found existing boltdb file, skipping setup wrapper {“system”: “docker”, “bolt_path”: “/var/lib/influxdb2/influxd.bolt”}
+ influx bucket create -n telegraf1 -r 52w -o ST -t randomTokenValue
+ wait 114
Error: listen tcp :8086: bind: address already in use
See ‘influxd -h’ for help
2021-08-05T04:41:43.235722100Z info found existing boltdb file, skipping setup wrapper {“system”: “docker”, “bolt_path”: “/var/lib/influxdb2/influxd.bolt”}
+ influx bucket create -n telegraf1 -r 52w -o ST -t randomTokenValue
+ wait 113
Error: listen tcp :8086: bind: address already in use
See ‘influxd -h’ for help
2021-08-05T04:42:23.429923400Z info found existing boltdb file, skipping setup wrapper {“system”: “docker”, “bolt_path”: “/var/lib/influxdb2/influxd.bolt”}
ts=2021-08-05T04:42:31.322425Z lvl=info msg=”Welcome to InfluxDB” log_id=0Vm9lS6W000 version=2.0.7 commit=2a45f0c037 build_date=2021-06-04T19:17:40Z
ts=2021-08-05T04:42:31.378521Z lvl=info msg=”Resources opened” log_id=0Vm9lS6W000 service=bolt path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:42:31.679453Z lvl=info msg=”Checking InfluxDB metadata for prior version.” log_id=0Vm9lS6W000 bolt_path=/var/lib/influxdb2/influxd.bolt
ts=2021-08-05T04:42:31.679700Z lvl=info msg=”Using data dir” log_id=0Vm9lS6W000 service=storage-engine service=store path=/var/lib/influxdb2/engine/data
ts=2021-08-05T04:42:31.679738Z lvl=info msg=”Compaction settings” log_id=0Vm9lS6W000 service=storage-engine service=store max_concurrent_compactions=4 throughput_bytes_per_second=50331648 throughput_bytes_per_second_burst=50331648
ts=2021-08-05T04:42:31.679755Z lvl=info msg=”Open store (start)” log_id=0Vm9lS6W000 service=storage-engine service=store op_name=tsdb_open op_event=start
ts=2021-08-05T04:42:31.679881Z lvl=info msg=”Open store (end)” log_id=0Vm9lS6W000 service=storage-engine service=store op_name=tsdb_open op_event=end op_elapsed=0.127ms
ts=2021-08-05T04:42:31.680032Z lvl=info msg=”Starting retention policy enforcement service” log_id=0Vm9lS6W000 service=retention check_interval=30m
ts=2021-08-05T04:42:31.680087Z lvl=info msg=”Starting precreation service” log_id=0Vm9lS6W000 service=shard-precreation check_interval=10m advance_period=30m
ts=2021-08-05T04:42:31.680189Z lvl=info msg=”Starting query controller” log_id=0Vm9lS6W000 service=storage-reads concurrency_quota=1024 initial_memory_bytes_quota_per_query=9223372036854775807 memory_bytes_quota_per_query=9223372036854775807 max_memory_bytes=0 queue_size=1024
ts=2021-08-05T04:42:31.684606Z lvl=info msg=”Configuring InfluxQL statement executor (zeros indicate unlimited).” log_id=0Vm9lS6W000 max_select_point=0 max_select_series=0 max_select_buckets=0
ts=2021-08-05T04:42:32.125749Z lvl=info msg=Starting log_id=0Vm9lS6W000 service=telemetry interval=8h
ts=2021-08-05T04:42:32.125882Z lvl=info msg=Listening log_id=0Vm9lS6W000 service=tcp-listener transport=http addr=:8086 port=8086
Waiting InfluxDB to start
+ influx bucket create -n telegraf1 -r 52w -o ST -t randomTokenValue
ts=2021-08-05T04:42:53.102927Z lvl=error msg=”Unable to cleanup bucket after create failed” log_id=0Vm9lS6W000 error=”bucket not found”
ts=2021-08-05T04:42:53.103000Z lvl=error msg=”api error encountered” log_id=0Vm9lS6W000 handler=bucket error=”bucket with name telegraf1 already exists”
Error: Failed to create bucket: bucket with name telegraf1 already exists.
See ‘influx bucket create -h’ for help
+ wait 111
Search…
Stick to bottom
I dont know…