Summary
This article shows you how to create a Python program that creates a Visual Studio Code c_cpp_properties.json which will enable intellisense when editing Linux Kernel Modules for Device Drivers.
Story
I am working my way through understanding, or at least trying to understand, Linux Kernel Modules – specifically Linux Device Drivers. I have been following through the book Linux Device Drivers Development by John Madieu

There are a bunch of example codes in the book which you can “git”
$ git remote -v
origin https://github.com/PacktPublishing/Linux-Device-Drivers-Development (fetch)
origin https://github.com/PacktPublishing/Linux-Device-Drivers-Development (push)
$
When I started looking at the Chapter02 example I first opened it up in Visual Studio Code. Where I was immediately given a warning about Visual Studio Code not knowing where to find <linux/init.h>
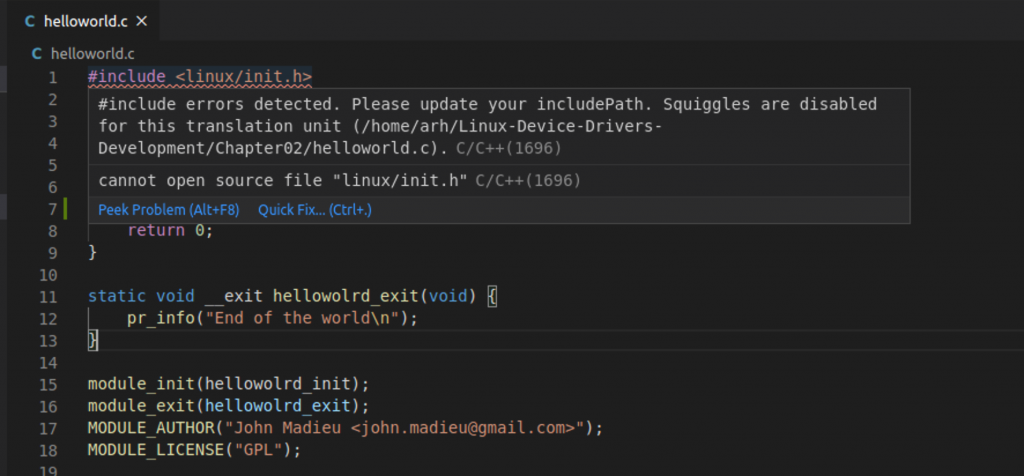
And, when you try to click on the “KERN_INFO” symboled you get this nice message.
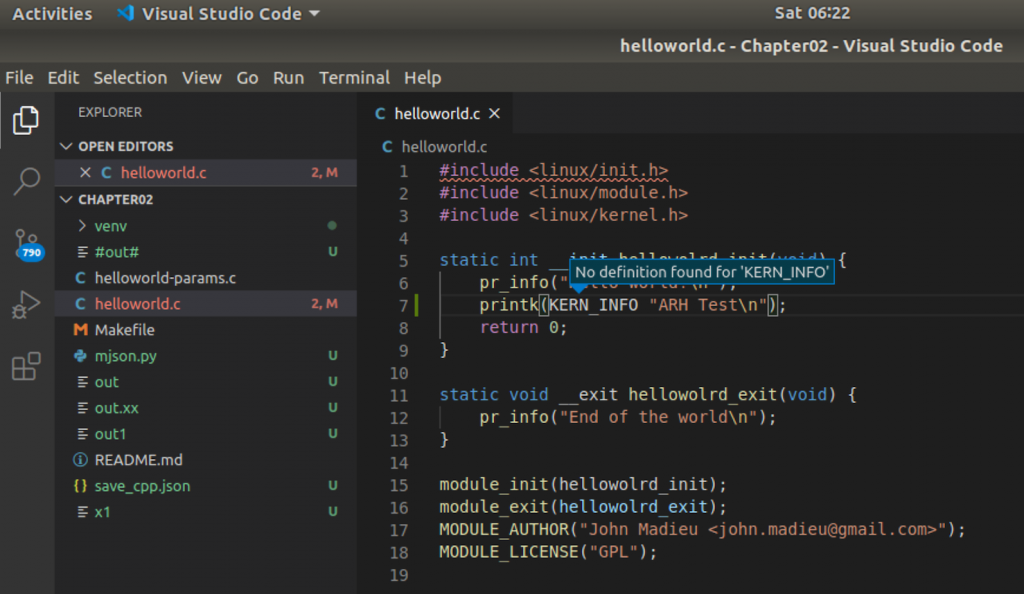
In order to fix this you need to setup the “c_cpp_propertiese.json” to tell Visual Studio Code how to make intellisense work correctly. But, what is c_cpp_properties.json?
C_CPP_PROPERTIES.JSON
On the Visual Studio Code website they give you a nice description of the schema. Here is a screenshot from their website.
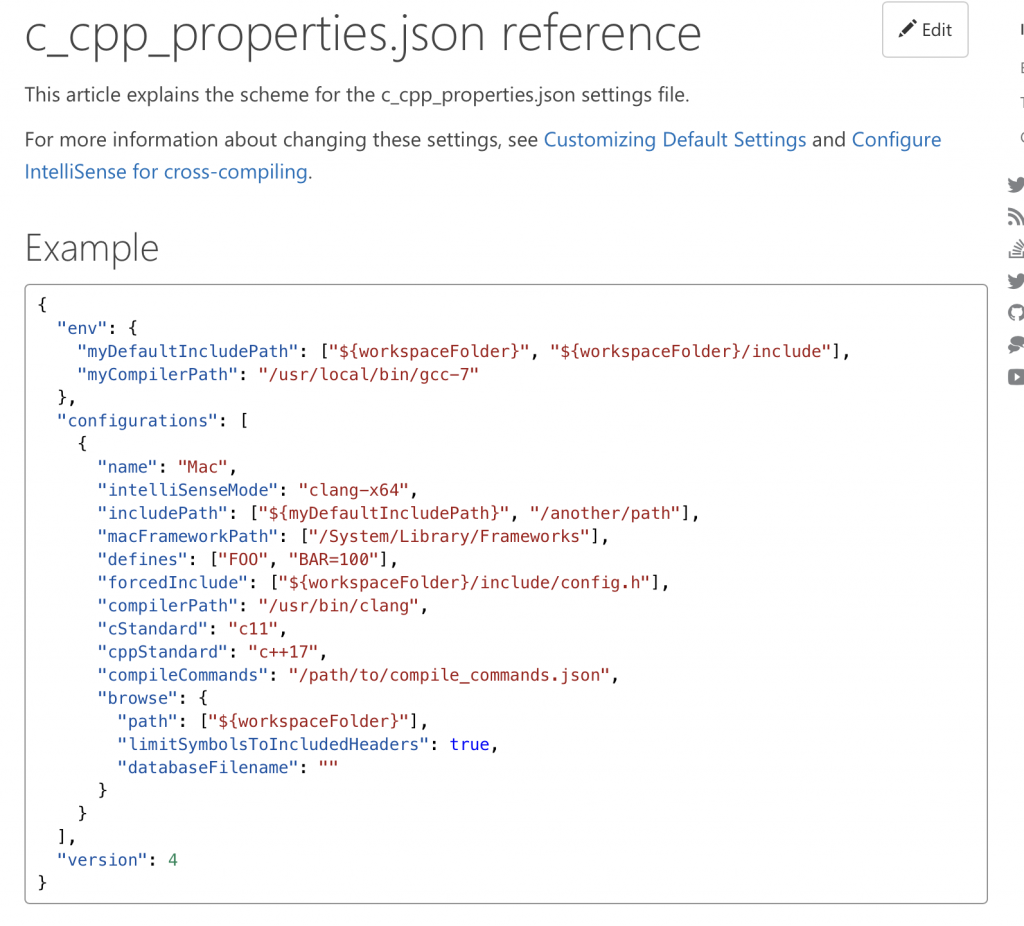
The “stuff” that seems to matter from this list is the “includePath” which tells intellisense the #includes and #defines. OK. How do I figure out where to find all of the files and paths for that?
make –dry-run
When you look at the Makefile it doesn’t appear to help very much. I don’t know about you guys, but I actually dislike “Make” way more than I dislike Python :-). What the hell is this Makefile telling you to do?
On line 3 the Makefile creates a variable called “KERNELDIR” and sets the value to the result of the shell command “uname -r” plus “/lib/modules” at the first and “/build” at the end. If I run the command “uname -r” on my system I get “4.15.0-99-generic”
Then on line 9 it calls make with a “-C” option
obj-m := helloworld-params.o helloworld.o
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
all default: modules
install: modules_install
modules modules_install help clean:
$(MAKE) -C $(KERNELDIR) M=$(shell pwd) $@
Which tells Make to “change directory”
$ make --help
Usage: make [options] [target] ...
Options:
-b, -m Ignored for compatibility.
-B, --always-make Unconditionally make all targets.
-C DIRECTORY, --directory=DIRECTORY
Change to DIRECTORY before doing anything
OK when I look in that directory I see a bunch of stuff. Most importantly a Makefile.
$ cd /lib/modules/4.15.0-99-generic/build
$ ls
arch crypto firmware init Kconfig Makefile net security ubuntu
block Documentation fs ipc kernel mm samples sound usr
certs drivers include Kbuild lib Module.symvers scripts tools virt
$
When I look in that Makefile I start to sweat because it is pages and pages of Make incantations. Now what?
# SPDX-License-Identifier: GPL-2.0
VERSION = 4
PATCHLEVEL = 15
SUBLEVEL = 18
EXTRAVERSION =
NAME = Fearless Coyote
# *DOCUMENTATION*
# To see a list of typical targets execute "make help"
# More info can be located in ./README
# Comments in this file are targeted only to the developer, do not
# expect to learn how to build the kernel reading this file.
# That's our default target when none is given on the command line
PHONY := _all
_all:
# o Do not use make's built-in rules and variables
# (this increases performance and avoids hard-to-debug behaviour);
# o Look for make include files relative to root of kernel src
MAKEFLAGS += -rR --include-dir=$(CURDIR)
# Avoid funny character set dependencies
unexport LC_ALL
LC_COLLATE=C
LC_NUMERIC=C
export LC_COLLATE LC_NUMERIC
All hope is not lost. I turns out that you can have make do a “dry run” which will tell you what are the commands that it is going to execute. Here is part of the output for the Chapter02 example. Unfortunately, that is some ugly ugly stuff right there. What am I going to do with that?
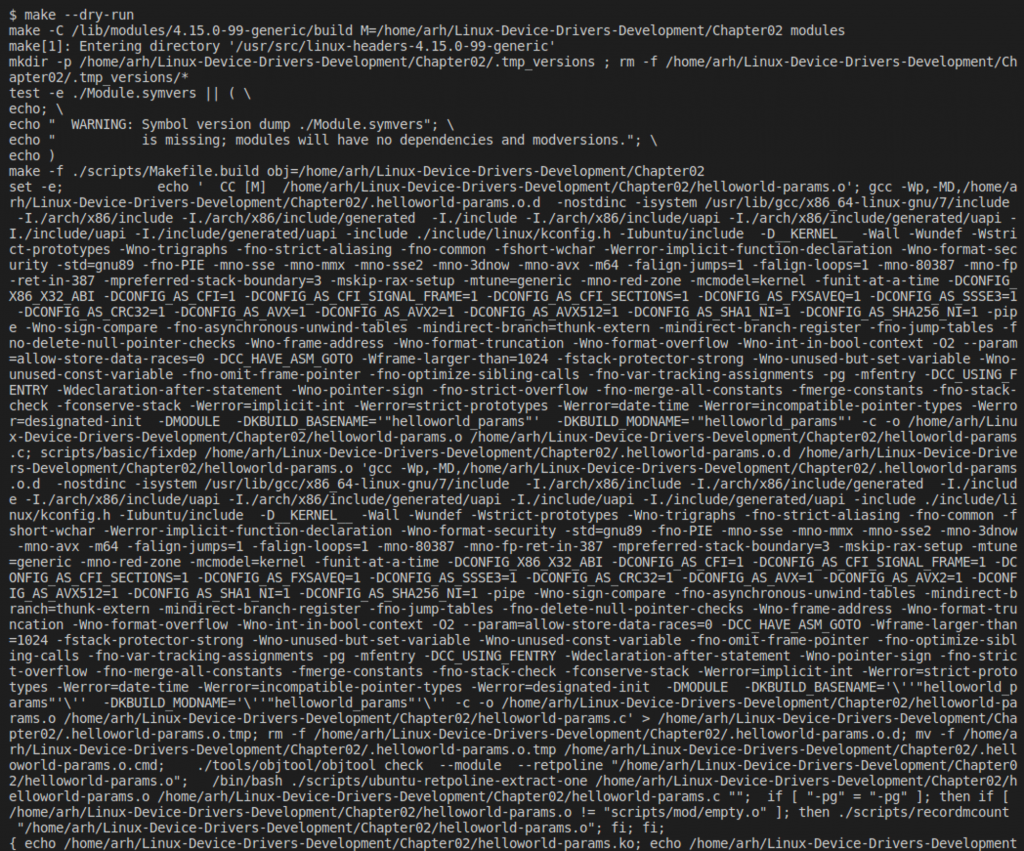
The answer is that I am going to do something evil – really evil. Which you already knew since this is an article about Python and Make you knew coming in that it was going to be evil. If you notice above there is a line that contains “…. CC [M] …” That is one of the lines where the compiler is actually being called. And you might notice that on the command line there are an absolute boatload of “-I” which is the gcc compiler option to add an include path.
The Python Program
What we are going to do here is write a Python program that does this:
- Runs make –dry-run
- Looks for lines with “CC”
- Splits the line up at the spaces
- Searches for “-I”s and adds them to a list of include paths
- Searches for “-D”s and adds them to a list of #defines
- Spits the whole mess out into a json file with the right format (from the Microsoft website)
I completely understand that this program is far far from a robust production worthy program. But, as it is written in Python, you should not be too surprised.
To start this program off I am going to use several Python libraries
- JSON
- OS (Operation System so that I can execute make and uname)
- RE (Regular expressions)
import json
import os
import re
The next thing to do is declare some global variables. The first three are Python Sets to hold one copy each of the includes, defines, other options and double dash options. The Python Set class allows you to add objects to a set that are guaranteed to be unique (if you attempt to add a duplicate it will be dropped)
includePath = set()
defines = set()
otherOptions = set()
doubleDash = set()
outputJson = dict()
The next block of code is a function that:
- Takes as an input a line from the makefile output
- Splits the line up into tokens by using white space. The split function take a string and divides it into a list.
- Then I iterate over the list (line 27)
- I use the Python string slicer syntax – the [] to grab part of the string. The syntax [:2] means give me the first two characters of the string
- I use 4 if statements to look to see if it is a “-I”, “-D”, “–” or “-” in which case I add it to the appropriate global variable.
Obviously this method is deeply hardcoded the output of this version of make on this operating system… but if you are developing Linux Device Drivers you are probably running Linux… so hopefully it is OK.
#
# Function: processLine
#
# Take a line from the make output
# split the line into a list by using whitespace
# search the list for tokens of
# -I (gcc include)
# -D (gcc #define)
# -- (I actually ignore these but I was curious what they all were)
# - (other - options which I keep track of ... but then ignore)
def processLine(lineData):
linelist = lineData.split()
for i in linelist:
if(i[:2] == "-I"):
if(i[2:2] == '/'):
includePath.add(i[2:])
else:
includePath.add(f"/usr/src/linux-headers-{kernelVersion}/{i[2:]}")
elif (i[:2] == "-D"):
defines.add(i[2:])
elif (i[:2] == "--"):
doubleDash.add(i)
elif (i[:1] == '-'):
otherOptions.add(i)
The next block of code runs two Linux commands (uname and make –dryrun) and puts the output into a string. On line 51 I split the make output into a list of strings one per line.
# figure out which version of the kernel we are using
stream = os.popen('uname -r')
kernelVersion = stream.read()
# get rid of the \n from the uname command
kernelVersion = kernelVersion[:-1]
# run make to find #defines and -I includes
stream = os.popen('make --dry-run')
outstring = stream.read()
lines = outstring.split('\n')
In the next block of code I iterate through the makefile output looking for lines that have the “CC” in them. I try to protect myself by requiring that the CC have white space before and after. Notice one line 56 that I use a regular expression to look for the “CC”.
for i in lines:
# look for a line with " CC "... this is a super ghetto method
val = re.compile(r'\s+CC\s+').search(i)
if val:
processLine(i)
The last block of code actually create the JSON and writes it to the output file c_cpp_properties.json.
# Create the JSON
outputJson["configurations"] = []
configDict = {"name" : "Linux"}
configDict["includePath"] = list(includePath)
configDict["defines"] = list(defines)
configDict["intelliSenseMode"] = "gcc-x64"
configDict["compilerPath"]= "/usr/bin/gcc"
configDict["cStandard"]= "c11"
configDict["cppStandard"] = "c++17"
outputJson["configurations"].append(configDict)
outputJson["version"] = 4
# Convert the Dictonary to a string of JSON
jsonMsg = json.dumps(outputJson)
# Save the JSON to the files
outF = open("c_cpp_properties.json", "w")
outF.write(jsonMsg)
outF.close()
Thats it. You can then:
- Run the program
- move the file c_cpp_properties.json in the .vscode directory
And now everything is more better 🙂 When I hover over the “KERN_INFO” I find that it is #define to “6”
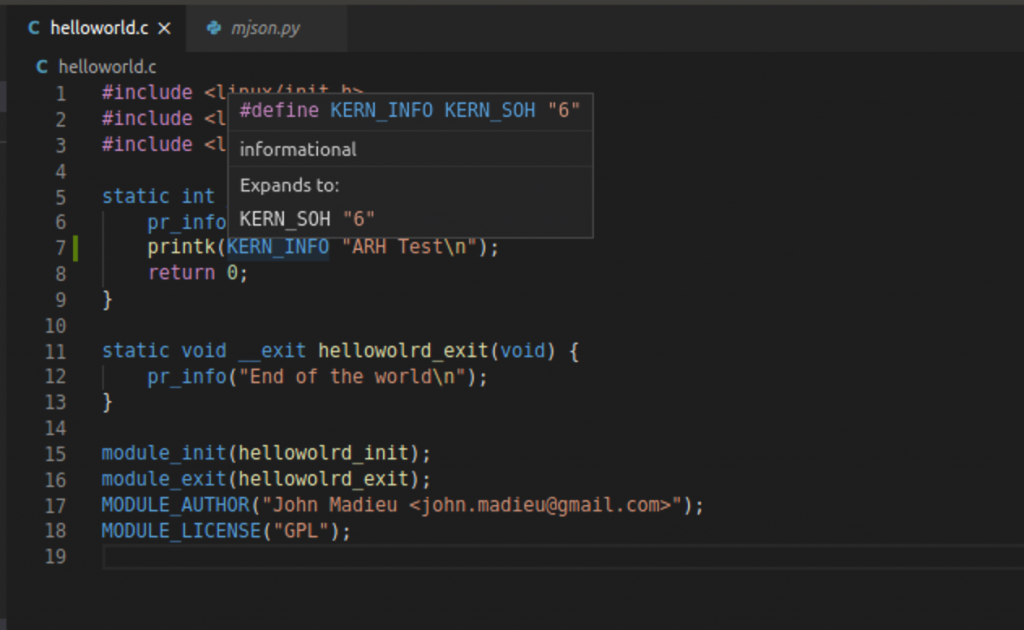
I will say that I am not a fan of having the compiler automatically concatenate two strings, but given that this article is written about a Python program who am I to judge?
What could go wrong?
There are quite a few things that could go wrong with this program.
- The make output format could change
- There could be multiple compiles that have conflicting options
- I could spontaneously combust from writing Python programs
- The hardcoded cVersion, cStandard, compilerPath, intelliSenseMode could change enough to cause problems
All of these things could be fixed, or at least somewhat mitigated. But I already spent more time down this rabbit hole that I really wanted.
The Final Program
# This program runs "make --dry-run" then processes the output to create a visual studio code
# c_cpp_properties.json file
import json
import os
import re
includePath = set()
defines = set()
otherOptions = set()
doubleDash = set()
outputJson = dict()
# Take a line from the make output
# split the line into a list by using whitespace
# search the list for tokens of
# -I (gcc include)
# -D (gcc #define)
# -- (I actually ignore these but I was curious what they all were)
# - (other - options which I keep track of ... but then ignore)
def processLine(lineData):
linelist = lineData.split()
for i in linelist:
if(i[:2] == "-I"):
if(i[2:2] == '/'):
includePath.add(i[2:])
else:
includePath.add(f"/usr/src/linux-headers-{kernelVersion}/{i[2:]}")
elif (i[:2] == "-D"):
defines.add(i[2:])
elif (i[:2] == "--"):
doubleDash.add(i)
elif (i[:1] == '-'):
otherOptions.add(i)
# figure out which version of the kernel we are using
stream = os.popen('uname -r')
kernelVersion = stream.read()
# get rid of the \n from the uname command
kernelVersion = kernelVersion[:-1]
# run make to find #defines and -I includes
stream = os.popen('make --dry-run')
outstring = stream.read()
lines = outstring.split('\n')
for i in lines:
# look for a line with " CC "... this is a super ghetto method
val = re.compile(r'\s+CC\s+').search(i)
if val:
processLine(i)
# Create the JSON
outputJson["configurations"] = []
configDict = {"name" : "Linux"}
configDict["includePath"] = list(includePath)
configDict["defines"] = list(defines)
configDict["intelliSenseMode"] = "gcc-x64"
configDict["compilerPath"]= "/usr/bin/gcc"
configDict["cStandard"]= "c11"
configDict["cppStandard"] = "c++17"
outputJson["configurations"].append(configDict)
outputJson["version"] = 4
# Convert the Dictonary to a string of JSON
jsonMsg = json.dumps(outputJson)
# Save the JSON to the files
outF = open("c_cpp_properties.json", "w")
outF.write(jsonMsg)
outF.close()